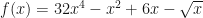This tutorial is on a Hidden Markov Model. What is a Hidden Markov Model and why is it hiding?

I have split the tutorial in two parts. Part 1 will provide the background to the discrete HMMs. I will motivate the three main algorithms with an example of modeling stock price time-series. In part 2 I will demonstrate one way to implement the HMM and we will test the model by using it to predict the Yahoo stock price!
A Hidden Markov Model (HMM) is a statistical signal model. This short sentence is actually loaded with insight! A statistical model estimates parameters like mean and variance and class probability ratios from the data and uses these parameters to mimic what is going on in the data. A signal model is a model that attempts to describe some process that emits signals. Putting these two together we get a model that mimics a process by cooking-up some parametric form. Then we add “Markov”, which pretty much tells us to forget the distant past. And finally we add ‘hidden’, meaning that the source of the signal is never revealed. BTW, the later applies to many parametric models.
Setting up the Scene
HMM is trained on data that contains an observed sequence of signals (and optionally the corresponding states the signal generator was in when the signals were emitted). Once the HMM is trained, we can give it an unobserved signal sequence and ask:
- How probable is that this sequence was emitted by this HMM? This would be useful for a problem like credit card fraud detection.
- What is the most probable set of states the model was in when generating the sequence? This would be useful for a problem of time-series categorization and clustering.
It is remarkable that the model that can do so much was originally designed in the 1960-ies! Here we will discuss the 1-st order HMM, where only the current and the previous model states matter. Compare this, for example, with the nth-order HMM where the current and the previous n states are used. Here, by “matter” or “used” we will mean used in conditioning of states’ probabilities. For example, we will be asking about the probability of the HMM being in some state 
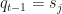
So far we have described the observed states of the stock price and the hidden states of the market. Let’s imagine for now that we have an oracle that tells us the probabilities of market state transitions. Generally the market can be described as being in bull or bear state. We will call these “buy” and “sell” states respectively. Table 1 shows that if the market is selling Yahoo stock, then there is a 70% chance that the market will continue to sell in the next time frame. We also see that if the market is in the buy state for Yahoo, there is a 42% chance that it will transition to selling next.
| Sell | Buy | |
|---|---|---|
| Sell | 0.70 | 0.30 |
| Buy | 0.42 | 0.58 |
The oracle has also provided us with the stock price changes probabilities per market state. Table 2 shows that if the market is selling Yahoo, there is an 80% chance that the stock price will drop below our purchase price of $32.4 and will result in negative PnL. We also see that if the market is buying Yahoo, then there is a 10% chance that the resulting stock price will not be different from our purchase price and the PnL is zero. As I said, let’s not worry about where these probabilities come from. It will become clear later on. Note that row probabilities add to 1.0
| Down | Up | Unchanged | |
|---|---|---|---|
| Sell | 0.80 | 0.15 | 0.05 |
| Buy | 0.25 | 0.65 | 0.10 |
It is February 10th 2016 and the Yahoo stock price closes at $27.1. If we were to sell the stock now we would have lost $5.3. Before becoming desperate we would like to know how probable it is that we are going to keep losing money for the next three days.

To put this in the HMM terminology, we would like to know the probability that the next three time-step sequence realised by the model will be {down, down, down} for t=1, 2, 3. This sequence of PnL states can be given a name 

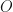
| Sell, Sell, Sell |
| Sell, Sell, Buy |
| Sell, Buy, Sell |
| Sell, Buy, Buy |
| Buy, Sell, Sell |
| Buy, Buy, Sell |
| Buy, Sell, Buy |
| Buy, Buy, Buy |
This gives rise to very long sum!

In total we need to consider 2*3*8=48 multiplications (there are 6 in each sum component and there are 8 sums). That is a lot and it grows very quickly. Please note that emission probability is tied to a state and can be re-written as a conditional probability of emitting an observation while in the state. If we perform this long calculation we will get 
Oracle is No More

In the previous section we have gained some intuition about HMM parameters and some of the things the model can do for us. However, the model is hidden, so there is no access to oracle! The state and emission transition matrices we used to make projections must be learned from the data. The hidden nature of the model is inevitable, since in life we do not have access to the oracle. In life we have access to historical data/observations and a magic methods of “maximum likelihood estimation” (MLE) and Bayesian inference. The MLE essentially produces distributional parameters that maximize the probability of observing the data at hand (i.e. it gives you the parameters of the model that is most likely have had generated the data). The HMM has three parameters 
- Given a sequence of observed values, provide us with a probability that this sequence was generated by the specified HMM. This can be re-phrased as the probability of the sequence occurring given the model. This is what we have calculated in the previous section.
- Given a sequence of observed values, provide us with the sequence of states the HMM most likely has been in to generate such values sequence.
- Given a sequence of observed values we should be able to adjust/correct our model parameters
,
and
.
When looking at the three ‘should’, we can see that there is a degree of circular dependency. That is, we need the model to do steps 1 and 2, and we need the parameters to form the model in step 3. Where do we begin? There are three main algorithms that are part of the HMM to perform the above tasks. These are: the forward&backward algorithm that helps with the 1st problem, the Viterbi algorithm that helps to solve the 2nd problem, and the Baum-Welch algorithm that puts it all together and helps to train the HMM model. Let’s discuss them next.
Going Back and Forth
That long sum we performed to calculate 

appears twice. The HMM Forward and Backward (HMM FB) algorithm does not re-compute these, but stores the partial sums as a cache. There are 


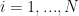
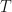
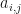

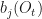
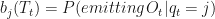




HMM FB calculates this sum efficiently by storing the partial sum calculated up to time 
- Start by initializing the “cache”
, where
.
- Calculate over all remaining observation sequences and states the partial sums:
, where
and
. Since at a single iteration we hold
constant, this results in a trellis-like calculation along the columns of the transition matrix.
- The probability is then given by
. This is where we gather the individual states probabilities together.
The above is the Forward algorithm which requires only 
- Start by initializing the end “cache”
, for
- Calculate over all remaining observation sequences and states the partial sums (moving back to the start of the observation sequence):
, where
and
The 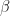

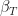
The State of the Affairs
We are now ready to solve the 2nd problem of the HMM – given the model and a sequence of observations, provide the sequence of states the model likely was in to generate such a sequence. Strictly speaking, we are after the optimal state sequence for the given 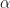
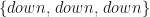

I have circled the values that are maximum. All of these correspond to the Sell market state. Our HMM would have told us that the most likely market state sequence that produced 
We are after the best state sequence 
- Start by initializing the end “cache”
, for
.
- Calculate over all remaining observation sequences and states the partial max and store away the index that delivers it:
, where
and
Update the sequence of indices of the max nodes as:
for j and t as above.
- Termination (probability and state):
- The optimal state sequence
is given by the path:
, for
![P*=\max_{1 \le i \le N} \small[\delta_{T}(i)\small]](https://s0.wp.com/latex.php?latex=P%2A%3D%5Cmax_%7B1+%5Cle+i+%5Cle+N%7D+%5Csmall%5B%5Cdelta_%7BT%7D%28i%29%5Csmall%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![q_{T}*=argmax_{1 \le i \le N} \small[\delta_{T}(i)\small]](https://s0.wp.com/latex.php?latex=q_%7BT%7D%2A%3Dargmax_%7B1+%5Cle+i+%5Cle+N%7D+%5Csmall%5B%5Cdelta_%7BT%7D%28i%29%5Csmall%5D&bg=ffffff&fg=111111&s=0&c=20201002)
Expect the Unexpected
And now what is left is the most interesting part of the HMM – how do we estimate the model parameters from the data? We will now describe the Baum-Welch Algorithm to solve this 3rd poised problem.
The reason we introduced the Backward Algorithm is to be able to express a probability of being in some state i at time t and moving to a state j at time t+1. Imagine again the probabilities trellis. Pick a model state node at time t, use the partial sums for the probability of reaching this node, trace to some next node j at time t+1, and use all the possible state and observation paths after that until T. This gives the probability of being in state 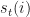
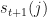

To make this transition into a proper probability, we need to scale it by all possible transitions in 

So, 
Summing 


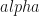

The (un-scaled)

So, what is 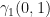


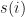




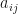
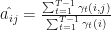
We can derive the update to 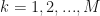




We now have the estimation/update rule for all parameters in
- Repeat until convergence:
- Initialize
to random values such that
,
and
. It is important to ensure that row probabilities add up to 1 and probabilities are not uniform as this may result in convergence to a local maximum.
- Compute
,
, and
and
- Re-estimate
The convergence can be assessed as the maximum change achieved in values of 
I hope some of you may find this tutorial revealing and insightful. I will share the implementation of this HMM with you next time.
Reference: L.R.Rabiner. An introduction to Hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2):257-268, 1989.