
In this blog I will show you what happens when you want to pickle an object that contains a Python namedtuple.
Python’s namedtuple is high-performance data type that lets us define a custom type which behaves like a tuple. For example, the following piece of code defines a new type Viewer, creates an instance of it and initialises its attributes:
from collections import namedtuple
Viewer = namedtuple('Viewer', 'gender age points')
viewer = Viewer('X', 25, 356)
In the above, line 3 defines a new type Viewer, and line 4 defines and initialises a new variable viewer of type Viewer. viewer behaves like a tuple in a sense that it has built-in methods count() and index() and allows access to attributes via indexing or named arguments. For example:
print(viewer[2]) # prints 356
print(viewer.age) # prints 25
print(viewer.count('X')) # prints 1
Note that unlike with a list or a dict, to work with namedtuples we need to perform two operations: (1) define the new type, (2) create a new instance of it. Also note that the same two steps are followed when we work with classes. And a namedtuple is just a dynamically named class type. But how exactly does this dynamic part works? It works because when we define a new type (line 3 in the first code snippet), we are actually calling a factory function namedtuple that does the dynamic ‘stuff’ for us (i.e. returns a sub-class of a tuple that is named as what we specify in the function call).
Let’s see what happens when we create a class with a namedtuple member.
import pickle
from collections import namedtuple
import datetime as dt
class ViewerClass(object):
# class-level type definition
vt = namedtuple(
'vt', 'start_date mon_views mon_streams name dob'
)
def __init__(
self, start_date, mon_views, mon_streams, name, dob
):
self._my_vt = ViewerClass.vt(
start_date, mon_views, mon_streams, name, dob
)
def get_start_date(self):
return self._my_vt.start_date
def get_monthly_views(self):
return self._my_vt.mon_views
def get_monthly_streams(self):
return self._my_vt.mon_streams
def get_registration_details(self):
return (
'Name:'
+ self._my_vt.name
+ ' DOB:'
+ str(self._my_vt.dob)
)
def update_monthly_stream(self, new_mon_streams):
self._my_vt.mon_streams = new_mon_streams
def update_monthly_views(self, new_mon_views):
self._my_vt.mon_views = new_mon_views
if __name__ == '__main__':
viewer1 = ViewerClass(
dt.date(2019, 1, 1),
5,
6234.80,
'John',
dt.date(1989, 12, 3),
)
print(
"Viewer {} has streamed for {} seconds this month.".format(
viewer1.get_registration_details(),
viewer1.get_monthly_streams(),
)
)
viewer2 = ViewerClass(
dt.date(2019, 2, 1),
5,
5234.80,
'Mary',
dt.date(1989, 11, 11),
)
print(
"Viewer {} has streamed for {} seconds this month.".format(
viewer2.get_registration_details(),
viewer2.get_monthly_streams(),
)
)
print(type(viewer1))
print(type(viewer1._my_vt))
The output of the print statements points to a potential problem that can occur if we try to pickle the viewer objects:

It turns out that the protected variable is of type ‘__main__.vt’ but not ‘__main__.ViewerClass.vt’. And if we try to pickle viewer1 we are going to get this error:
_pickle.PicklingError: Can’t pickle <class ‘__main__.vt’>: attribute lookup vt on __main__ failed
This error should make sense because vt is not defined within __main__, but is defined within __main__.ViewerClass, and thus is not visible to pickle as a subclass of a class.
There are several ways to fix this.
First, we can move the definition of vt outside of ViewerClass to the __main__. This will let pickle find vt at the level it is looking for it:
# module-level type definition
vt = namedtuple(
'vt', 'start_date mon_views mon_streams name dob'
)
class ViewerClass(object):
def __init__(
self, start_date, mon_views, mon_streams, name, dob
):
self._my_vt = vt(
start_date, mon_views, mon_streams, name, dob
)
...
Second solution involves changing a built-in private variable __qual_name__ to that of the class name:
import pickle
from collections import namedtuple
import datetime as dt
class ViewerClass(object):
# class-level definition
vt = namedtuple(
'vt', 'start_date mon_views mon_streams name dob'
)
vt.__qualname__ = 'ViewerClass.vt'
def __init__(
self, start_date, mon_views, mon_streams, name, dob
):
self._my_vt = ViewerClass.vt(
start_date, mon_views, mon_streams, name, dob
)
...
This fixes the issue and makes viewer1._my_vt of type ‘__main__.ViewerClass.vt’, under which pickle can look it up.
I must say that I prefer the first solution, since sub-classing from the ViewerClass may prove to be problematic, and we should avoid modifying private variables.
![Sample from f(x)=2.0*exp(-2*x) over [0.01, 3.0]](https://codefying.com/wp-content/uploads/2016/10/rejfig_1.png?w=300&h=224)




 and
and 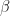 require to be scaled for longer observations since the product of probabilities quickly tends to zero, resulting in underflow. The code has a flag for scaling, and defaults to positive.
require to be scaled for longer observations since the product of probabilities quickly tends to zero, resulting in underflow. The code has a flag for scaling, and defaults to positive. and
and  makes a big difference to the final solution. I am providing two possible assignments. One, as described in part 1, setting approximately to the same values, adding to 1. And two, using Dirichlet distribution to create non-uniform assignment that adds-up to 1. I’ve noticed that the former results in more meaningful model parameters.
makes a big difference to the final solution. I am providing two possible assignments. One, as described in part 1, setting approximately to the same values, adding to 1. And two, using Dirichlet distribution to create non-uniform assignment that adds-up to 1. I’ve noticed that the former results in more meaningful model parameters. to the maximum observation in
to the maximum observation in 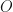 . This is needed because not all observation sequences will contain all values (i.e. 0, 1, 2). And the transition and emission matrices are accessed as if all the values exist.
. This is needed because not all observation sequences will contain all values (i.e. 0, 1, 2). And the transition and emission matrices are accessed as if all the values exist. :
: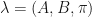 are very sensitive to the convergence tolerance, initial assignment and, obviously the training time-window. Calculating accuracy ratio as the number of correctly predicted directions is pretty much around 50%-56% (tests on more recent data produce the higher accuracy in this range). Thus, we might as well be throwing a coin to make buy or sell predictions. It is possible that EOD price moves are not granular enough to provide a coherent market dynamic model.
are very sensitive to the convergence tolerance, initial assignment and, obviously the training time-window. Calculating accuracy ratio as the number of correctly predicted directions is pretty much around 50%-56% (tests on more recent data produce the higher accuracy in this range). Thus, we might as well be throwing a coin to make buy or sell predictions. It is possible that EOD price moves are not granular enough to provide a coherent market dynamic model.