
In my previous post here I have shared with you some methods for generating uniform random variables. For many practical tasks we need random variables that are distributed normally around some mean. There are two well know approaches for transforming uniform random variables to normal or Gaussian. These are – the inverse transform and the Box-Muller methods. Let’s take a look at each of them. I am also providing my version of C# implementation.
Inverse Transform Method
The general form of this method is:
![X=F^{-1} (U),U\approx Unif[0,1]](https://s0.wp.com/latex.php?latex=X%3DF%5E%7B-1%7D+%28U%29%2CU%5Capprox+Unif%5B0%2C1%5D&bg=ffffff&fg=111111&s=0&c=20201002)
Here U is a uniform random variable from [0,1] interval, 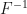
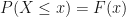
To make sense of this method and to see why it works, let’s take a look at the graph of a normal c.d.f. where 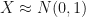

I hope by now it is clear how the inverse transform method works. The main reason it always works for a well-behaved distribution like the normal distribution is because the ‘mapping’ is one-to-one. That is, for each value of U, we have a unique mapping onto X. A good intuitive way to think about the inverse transform method is by analogy to taking a percentile of some distribution.
The standard normal cumulative distribution function is:

To use the inverse transform method we need to take the inverse, or calculate
In [1] we find a summary of the rational approximation proposed by Beasley and Springer:

Where 

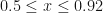

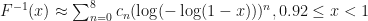
The values below 0.5 can be derived by symmetry. The above method gives a high accuracy with a maximum absolute error of 
A less accurate method involves approximating the error function erf, since the inverse c.d.f. can be defined in terms of erf as follows:
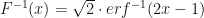
The inverse error function can be approximated using:

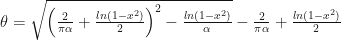
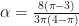
This approach achieves a maximum absolute error of 0.00035 for all x. To me, the erf method is simpler, both, to understand and to implement.
Box-Muller Method
Box-Muller method for transforming uniform random variables to normal r.vs. is an algorithms that involves choosing a random point uniformly from the circle of radius 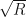


Box-Muller method requires two uniform random variables, and it produces two standard normal random variables. The reason for having two, is because we are simulating a point on a circle in x,y plane. So, to pick a random point on a circle we need a radius and the angle it makes with the origin. If we can randomise the radius and the angle with the origin (using the two random uniforms), we can achieve a random way of simulating the (x,y) point on a circle. Take a look at Figure 2 below, which demonstrates this concept.

Ok, hopefully the above gives you a clear explanation for the foundations of the inverse transform and the Box-Muller methods. Let’s now look at how we can implement them in C#.
Implementation
Box-Muller class has an overloaded method that works for a single pair or a 2D array of r.v.s:
internal sealed class BoxMuller
{
/// <summary>
/// Returns an arrays with Z1 and Z2 - two standard normal random variables generated using Box-Muller method
/// </summary>
/// <param name="U1">first standard random uniform</param>
/// <param name="U2">second standard randoom uniform</param>
/// <returns>double[] of length=2</returns>
internal double[] BoxMullerTransform(double U1, double U2)
{
double[] normals = new double[2];
if (U1 < 0 || U1 > 1 || U2 < 0 || U2 > 1)
{
normals[0] = default(double);
normals[1] = default(double);
}
else
{
double sqrtR = Math.Sqrt(-2.0*Math.Log(U1));
double v = 2.0*Math.PI*U2;
normals[0] = sqrtR * Math.Cos(v);
normals[1] = sqrtR * Math.Sin(v);
}
return normals;
}
/// <summary>
/// Returns a 2D array with Z1[] and Z2[] - two standard normal random variables generated using Box-Muller method
/// </summary>
/// <param name="U1">u1[] an array of first standard random uniforms</param>
/// <param name="U2">u2[] an array of second standard random uniforms</param>
/// <returns>double[L,2] of L=min(Length(u1),Length(u2))</returns>
internal double[,] BoxMullerTransform(double[] U1, double[] U2)
{
long count=U1.Length<=U2.Length?U1.Length:U2.Length;
double[,] normals = new double[count, 2];
double u1, u2;
for (int i = 0; i < count; i++)
{
u1 = U1[i];
u2 = U2[i];
if (u1 < 0 || u1 > 1 || u2 < 0 || u2 > 1)
{
normals[i,0] = default(double);
normals[i,1] = default(double);
}
else
{
double sqrtR = Math.Sqrt(-2.0 * Math.Log(u1));
double v = 2.0 * Math.PI * u2;
normals[i,0] = sqrtR * Math.Cos(v);
normals[i,1] = sqrtR * Math.Sin(v);
}
}
return normals;
}
}
The inverse transform has four internal methods for generating normal r.v.s. As described before, the ERF method is simpler, and is also easier to implement. The Beasley-Springer-Moro (BSM) method is based on the algorithm found in [1], pg. 68. I’ve verified that it gives an accurate solution up to 9.d.p. Note that InverseTransformERF is an approximation to InverseTransformMethod, and it seems to achieve an accuracy of up to 4 d.p.
internal sealed class InverseTransform
{
/// <summary>
/// Returns a standard normal random variable given a standard uniform random variable
/// </summary>
/// <param name="x">standard uniform rv in [0,1]</param>
/// <returns>standard normal rv in (-3,3)</returns>
internal double InverseTransformMethod(double x)
{
if (x < 0 || x > 1)
return default(double);
double res,r;
double y = x - 0.5;
if(y<0.42)
{
r = y * y;
res = y * (((a3 * r + a2) * r + a1) * r + a0) / ((((b3 * r + b2) * r + b1) * r + b0) * r + 1.0);
}
else
{
r = (y > 0) ? (1 - x) : x;
r = Math.Log(-1.0 * Math.Log(r));
res = c0 + r * (c1 + r * (c2 + r * (c3 + r * (c4 + r * (c5 + r * (c6 + r * c7 + r * c8))))));
res = (y < 0) ? -1.0 * res : res;
}
return res;
}
/// <summary>
/// Returns an array of standard normal random variables given an array of standard uniform random variables
/// </summary>
/// <param name="x">an array of doubles: uniform rvs in [0,1]</param>
/// <returns>an array of doubles: standard normal rvs in (-3,3)</returns>
internal double[] InverseTransformMethod(double[] x)
{
long size = x.Length;
double[] res = new double[size];
double r,y;
for (int i = 0; i < size;i++)
{
if (x[i]<0 || x[i]>1)
{
res[i] = 0;
continue;
}
y = x[i] - 0.5;
if (y < 0.42)
{
r = y * y;
res[i] = y * (((a3 * r + a2) * r + a1) * r + a0) / ((((b3 * r + b2) * r + b1) * r + b0) * r + 1.0);
}
else
{
r = (y > 0) ? (1 - x[i]) : x[i];
r = Math.Log(-1.0 * Math.Log(r));
res[i] = c0 + r * (c1 + r * (c2 + r * (c3 + r * (c4 + r * (c5 + r * (c6 + r * c7 + r * c8))))));
res[i] = (y < 0) ? -1.0 * res[i] : res[i];
}
}
return res;
}
/// <summary>
/// Performs an inverse transform using erf^-1
/// Returns a standard normal random variable given a standard uniform random variable
/// </summary>
/// <param name="x">standard uniform rv in [0,1]</param>
/// <returns>standard normal rv in (-3,3)</returns>
internal double InverseTransformERF(double x)
{
return Math.Sqrt(2.0) * InverseErf(2.0 * x - 1);
}
/// <summary>
/// Performs an inverse transform using erf^-1
/// Returns an array of standard normal random variables given an array of standard uniform random variables
/// </summary>
/// <param name="x">an array of doubles: uniform rvs in [0,1]</param>
/// <returns>an array of doubles: standard normal rvs in (-3,3)</returns>
internal double[] InverseTransformERF(double[] x)
{
long size = x.Length;
double[] res = new double[size];
for (int i = 0; i < size; i++ )
{
res[i] = Math.Sqrt(2.0) * InverseErf(2.0 * x[i] - 1);
}
return res;
}
private double InverseErf(double x)
{
double res;
double K = scalor + (Math.Log(1 - x * x)) / (2.0);
double L=(Math.Log(1-x*x))/(alpha);
double T = Math.Sqrt(K*K - L);
res = Math.Sign(x) * Math.Sqrt(T-K);
return res;
}
//used by the ERF method
private const double alpha = (8.0 * (Math.PI - 3.0)) / (3.0 * Math.PI * (4.0 - Math.PI));
private const double scalor = (2.0) / (Math.PI * alpha);
//used by the BSM method in "Monte Carlo Methods in Financial Engineering" by P.Glasserman
//note that a double achieves 15-17 digit precision
//since these constancts are small, we are not using decimal type
private const double a0 = 2.50662823884;
private const double a1 = -18.61500062529;
private const double a2 = 41.39119773534;
private const double a3 = -25.44106049637;
private const double b0 = -8.47351093090;
private const double b1 = 23.08336743743;
private const double b2 = -21.06224101826;
private const double b3 = 3.13082909833;
private const double c0 = 0.3374754822726147;
private const double c1 = 0.9761690190917186;
private const double c2 = 0.16079797149118209;
private const double c3 = 0.0276438810333863;
private const double c4 = 0.0038405729373609;
private const double c5 = 0.0003951896511919;
private const double c6 = 0.0000321767881768;
private const double c7 = 0.0000002888167364;
private const double c8 = 0.0000003960315187;
}
Surely the two different methods map the uniforms to different normal r.v.s. So, how can we compare these two methods? One way would be to consider simplicity, speed and the accuracy vs. the exact solution.
References:
[1]P. Glasserman. “Monte Carlo Methods in Financial Engineering”, 2004. Springer-Verlag.
