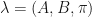This is the 2nd part of the tutorial on Hidden Markov models. In this post we will look at a possible implementation of the described algorithms and estimate model performance on Yahoo stock price time-series.
Implementation of HMM in Python
I am providing an example implementation on my GitHub space. Please note that all code is provided with a disclaimer that you are free to use it at your own risk. HMM.py contains the main implementation. There are a few things to point out in this file:
- As is pointed out in the referenced document in part 1,
and
require to be scaled for longer observations since the product of probabilities quickly tends to zero, resulting in underflow. The code has a flag for scaling, and defaults to positive.
- While testing out this model I noticed that initial assignment of
and
makes a big difference to the final solution. I am providing two possible assignments. One, as described in part 1, setting approximately to the same values, adding to 1. And two, using Dirichlet distribution to create non-uniform assignment that adds-up to 1. I’ve noticed that the former results in more meaningful model parameters.
- You will notice a small hack in HMMBaumWelch method where I am setting
to the maximum observation in
. This is needed because not all observation sequences will contain all values (i.e. 0, 1, 2). And the transition and emission matrices are accessed as if all the values exist.
- I am using yahoo_finance Python module to source the stock prices for Yahoo. It seems to work and is pretty easy to use. You should be able to download this module here.
HMM Model performance to predict Yahoo stock price move
On my github space, HMM_test.py contains a possible test example code. I am testing the model as following: train the model on a specified window of daily historical moves (e.g. 10 days) and using the model parameters determine the predicted current model state. Then, using the predicted state, determine the next likely state from 
prediction_state = np.argmax(a[path[-1],:])
The most likely emitted value from that state can be found as follows:
prediction = np.argmax(b[prediction_state,:])
I then compare the predicted move to the historical one. So, how did HMM do? Well, not so well. The model parameters