
Last week I was lucky enough to attend the Strata Conference London 2017 for one day. The venue and the event are impressive in scale, participants and content. The quality of tutorials and talks, in general, was very good, and I have walked away with a few new ideas I wanted to share on my blog.
One of the most important lessons from the conference for me was from a reference to the NIPS’16 paper titled Hidden Technical Debt in Machine Learning System, written by Google researchers. The paper is about the long-term maintenance costs introduced by building machine learning (ML) models and systems. The argument is that such cost is hidden as it is not immediately apparent from the point of putting an ML model in production. For data scientists it is important to be aware of the complexity of the models they develop and what impact these models will have on their organisation and how much it will cost to maintain them.
According to the authors, there are three levels of technical complexity which contribute to technical debt in ML: the model itself can be complex and behave non-linearly to a given set of parameters, the model can be taking input from otherwise disparate systems, and the model’s output or its behavior can be complex and difficult to predict before it is released.
ML Model Complexity
ML models entangle input signals from different systems together, making it difficult to avoid the CACE principle: Change Anything Change Everything. This principle applies to all aspects of ML, from parameters (think xgboost!), to input data to convergence thresholds and sampling methods. Isolation and servicing of modelling components is one of the proposed solutions.
The Cost of Data Dependencies
Large ML systems have large and complex data dependencies, where data quality and any data assumptions can significantly affect the ML system output. ML system input data can be unstable, meaning it changes qualitatively and quantitatively over time. In some cases, the degree of dependency on one set of data vs. another may change. The ML systems are unique because usually their data dependencies are finer (e.g. the input should not just be an integer, but an integer in a certain range). A lot of thinking and possibly investment should go into understanding such dependencies and controlling them. Check-out kensu.io – a start-up company I have come across at the conference, the creators of Adalog – a product designed purely for such task.
The Feedback Loop and Dealing with Changes
Live ML systems learn in real time and influence their own behavior. Sometimes it is necessary to choose static parameters, like prediction thresholds, for a model that is trained or parameterised on data that is dynamic in nature. Thus leading to the previous set of thresholds being no longer valid on updated data. The authors highlight that comprehensive monitoring of ML system behavior is critical for long-term system reliability.
In summary, maintainable ML systems are costly and require an even higher level of technical competence and foresight among its developers. ML models testing, validation and monitoring should be considered as an absolute must in organisations that are eager to rip their full benefits.
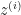 is a training input variable, then
is a training input variable, then  is the target class predicted by the learning hypothesis
is the target class predicted by the learning hypothesis  . It is clear that we want to minimize the distance between the predicted and the actual class value
. It is clear that we want to minimize the distance between the predicted and the actual class value 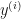 , thus the sum-squared-error is defined as
, thus the sum-squared-error is defined as  . The 1/2 in front of the sum is added to simplify the 1st derivative, which is taken to find the coefficients of regression when performing gradient descent. But one could easily define the cost function without the 1/2 term.
. The 1/2 in front of the sum is added to simplify the 1st derivative, which is taken to find the coefficients of regression when performing gradient descent. But one could easily define the cost function without the 1/2 term.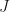 . This is a very intuitive optimal value problem describing what we are after. It is like asking TomTom to find the shortest route to Manchester from London to save money on fuel. No problems! Done. A gradient descend (batch or stochastic) will produce a vector of weights
. This is a very intuitive optimal value problem describing what we are after. It is like asking TomTom to find the shortest route to Manchester from London to save money on fuel. No problems! Done. A gradient descend (batch or stochastic) will produce a vector of weights 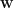 , which when multiplied into the matrix of training input variables
, which when multiplied into the matrix of training input variables  gives the optimal solution. So, the meaning of equation below should now be, hopefully, clear:
gives the optimal solution. So, the meaning of equation below should now be, hopefully, clear: (1)
(1) , we would like to find the most probable hypothesis
, we would like to find the most probable hypothesis  that fits the training data
that fits the training data  well.
well.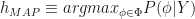 (2)
(2)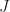 . In (2) we have a conditional probability. Using Bayes theorem, we can further develop it as:
. In (2) we have a conditional probability. Using Bayes theorem, we can further develop it as:
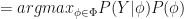 (3)
(3) is the probability of observing the training data. We drop this term because it is a constant and is independent of
is the probability of observing the training data. We drop this term because it is a constant and is independent of 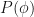 is a prior probability of some hypothesis. If we assume that every hypothesis in
is a prior probability of some hypothesis. If we assume that every hypothesis in  (4)
(4) (5)
(5) (6)
(6) is to find the coefficients that minimize the cost function. The problem here is that logit function is not smooth and convex and has many local minimums. In order to be able to use an optimal search procedure like gradient descend, we need to make the cost function convex. This is often done by taking the logarithm. Taking the log and negating (6) gives the familiar formula for the cost function J, which can also be found in chapter 3 of [2]:
is to find the coefficients that minimize the cost function. The problem here is that logit function is not smooth and convex and has many local minimums. In order to be able to use an optimal search procedure like gradient descend, we need to make the cost function convex. This is often done by taking the logarithm. Taking the log and negating (6) gives the familiar formula for the cost function J, which can also be found in chapter 3 of [2]:![J(w) = \sum_{i=1}^{n} \left[ -y^{(i)} \log(\phi (z^{(i)})) - (1-y^{(i)}) \log(1- \phi(z^{(i)})) \right]](https://s0.wp.com/latex.php?latex=J%28w%29+%3D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%C2%A0%5Cleft%5B+%C2%A0-y%5E%7B%28i%29%7D+%5Clog%28%5Cphi+%28z%5E%7B%28i%29%7D%29%29+-%C2%A0%281-y%5E%7B%28i%29%7D%29+%5Clog%281-+%5Cphi%28z%5E%7B%28i%29%7D%29%29+%5Cright%5D&bg=ffffff&fg=111111&s=0&c=20201002) (7)
(7)