
Greetings, my blog readers!
In this post I will tackle the link between the cost function and the maximum likelihood hypothesis. The idea for this post came to me when I was reading Python Machine Learning by Sebastian Raschka; the chapter on learning the weights on logistic regression classifier. I like this book and strongly recommend it to anyone interested in the field. It has solid Python coding example, many practical insights and a good coverage of what scikit-learn has to offer.
So, in chapter 3, section on Learning the weights of the logistic cost function, the author seamlessly moves from the need to minimize the sum-squared-error cost function to maximizing the (log) likelihood. I think that it is very important to have a clear intuitive understanding on why the two are equivalent in case of regression. So, let’s dive in!
Sum of Squared Errors
Using notation from [2], if 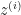


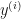

The sum-squared error is a cost function. We want to find a classifier (alternatively, a learning hypothesis) that minimizes this cost. Let’s call it 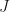
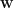


The MAP Hypothesis
The MAP hypothesis is a maximum a posteriori hypothesis. It is the most probable hypothesis given the observed data (note, I am using material from chapter 6.2 from [1] for this section). Out of all the candidate hypotheses in 


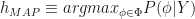
It should become intuitively obvious that, in case of a regression model, the most probable hypothesis is also the one that minimizes 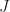

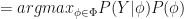

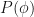

How did we go from looking for a hypothesis given the data to the data given the hypothesis? A hypothesis that results in the most probable frequency distribution for the training data is also the one that is the most accurate about it. Being the most accurate implies having the best fit (if we were to generate new data under MAP, it would fit the training data best, among all other possible hypotheses). Thus, MAP and ML are equivalent here.
Bringing in the Binary Nature of Logistic Regression
Under the assumption of independent n training data points, we can rewrite (4) as a product over all observations:

Because logistic regression is a binary classification, each data point can be either from a positive or a negative target class. We can use Bernoulli distribution to model this probability frequency:

Let’s recollect that in logistic regression the hypothesis is a logit function that takes a weighted sum of predictors and coefficients as input. Also, a single hypothesis 
![J(w) = \sum_{i=1}^{n} \left[ -y^{(i)} \log(\phi (z^{(i)})) - (1-y^{(i)}) \log(1- \phi(z^{(i)})) \right]](https://s0.wp.com/latex.php?latex=J%28w%29+%3D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%C2%A0%5Cleft%5B+%C2%A0-y%5E%7B%28i%29%7D+%5Clog%28%5Cphi+%28z%5E%7B%28i%29%7D%29%29+-%C2%A0%281-y%5E%7B%28i%29%7D%29+%5Clog%281-+%5Cphi%28z%5E%7B%28i%29%7D%29%29+%5Cright%5D&bg=ffffff&fg=111111&s=0&c=20201002)
Summary
In this post I made an attempt to show you the connection between the usually seen sum-of-squared errors cost function (which is minimized) and the maximum likelihood hypothesis (which is maximized).
References:
[1] Tom Mitchel, Machine Learning, McGraw-Hill, 1997.*
[2] Sebastian Raschka, Python Machine Learning, Packt Publishing, 2015.
* If there is one book on machine learning that you should read, it should be this one.
