
Greetings,
This is a short post to share two ways (there are many more) to perform pain-free linear regression in python. I will use numpy.poly1d and sklearn.linearmodel.
Using numpy.polyfit we can fit any data to a specified degree polynomial by minimizing the least square error method (LSE). LSE is the most common cost function for fitting linear models. It is calculated as a the sum of squared differences between the predicted and the actual values. So, let’s say we have some target variable y that is generated according to some function of x. In real life situations we almost never deal with a perfectly predictable function that generates the target variable, but have a lot of noise. However, let’s assume for simplicity that our function is perfectly predictable. Our task is to come up with a model (i.e. learn the polynomial coefficients and select the best polynomial degree) to explain the target variable y. The function for the data is:
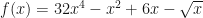
I will start by generating the train and the test data from 1,000 points:
import numpy as np from sklearn import linear_model from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import Pipeline import matplotlib.pyplot as plt # implement liner regression with numpy and sklearn # 1. Generate some random data np.random.seed(seed=0) size=1000 x_data = np.random.random(size) y_data=6*x_data-32*x_data**4-x_data**2-np.sqrt(x_data) # -32x^4-x^2+6x-sqrt(x) # 2. Split equally between test and train x_train=x_data[:size/2] x_test = x_data[size/2:] y_train=y_data[:size/2] y_test = y_data[size/2:]
We will test polynomials with degrees 1, 2 and 3. To use numpy.polyfit, we only need 2 lines of code. To use the sklearn, we need to transform x to a polynomial form with the degrees we are testing at. For that, we need to use sklearn.preprocessing.PolynomialFeatures. So, we proceed to generate 3 models and calculate the final LSE as follows:
plot_config=['bs', 'b*', 'g^']
plt.plot(x_test, y_test, 'ro', label="Actual")
# 3. Set the polynomial degree to be fitted betwee 1 and 3
top_degree=3
d_degree = np.arange(1,top_degree+1)
for degree in d_degree:
poly_fit = np.poly1d(np.polyfit(x_train,y_train, degree))
# print poly_fit.coeffs
# 4. Fit the numpy polynomial
predict=poly_fit(x_test)
error=np.mean((predict-y_test)**2)
print "Error with poly1d at degree %s is %s" %(degree, error)
# 5. Create a fit a polynomial with sk-learn LinearRegression
model = Pipeline([('poly', PolynomialFeatures(degree=degree)),('linear', linear_model.LinearRegression())])
model=model.fit(x_train[:,np.newaxis], y_train[:,np.newaxis])
predict_sk=model.predict(x_test[:,np.newaxis])
error_sk=np.mean((predict_sk.flatten()-y_test)**2)
print "Error with sk-learn.LinearRegression at degree %s is %s" %(degree, error_sk)
#plt.plot(x_test, y_test, '-', label="Actual")
plt.plot(x_test, predict, plot_config[degree-1], label="Fit "+str(degree)+ " degree poly")
plt.legend(bbox_to_anchor=(0., 1.02, 1., .102), loc=3,
ncol=2, mode="expand", borderaxespad=0.)
plt.show()
Showing the final results (from numpy.polyfit only) are very good at degree 3. We could have produced an almost perfect fit at degree 4. The two method (numpy and sklearn) produce identical accuracy. Under the hood, both, sklearn and numpy.polyfit use linalg.lstsq to solve for coefficients.


