In this post I would like to share with you two interesting visual insights into the effects of multicollinearity among the predictor variables on the coefficients of least squares regression (LSR). This post is very non-technical and I skip over most mathematical details. One of these insights is borrowed from Using Multivariate Statistics by Barbara Tabachnick and Linda Fidell (2013, 6th edition). When I first received it by post, after purchasing it on amazon, I immediately wanted to return it back. The paperback edition is the size of two large bricks and weighs 2.2 kg! I remember paging through it and thinking why on earth did this book receive so many good reviews on amazon. Only when I started reading it I understood why. This book is indispensable in providing clear and intuitive insight into topics like LSR, logistic regression, PCA and DA, canonical correlation, data cleaning and pre-processing, and many others. The source of the second insight is an online stats course offered by the Pennsylvania State University, which I find to be very good. Now that I am done with the credits, let’s see what the insights are!
I Thought you Said White with No Sugar?
Ok, so you probably know that multi/collinearity and singularity among predictor variables in regression is bad. But why is it bad and what does it affect? Multicollinearity is defined as a high (>90%) correlation among two or more predictor variables or their combinations (e.g. structural multicollinearity). Singularity can be simply defined as predictor redundancy. The presence of collinearity affects stability and interpretability of the regression model. By stability I mean what happens to the regression coefficients when new data points or new predictor variables are added in. By predictability I mean the usefulness of the magnitude and sign of the regression coefficients in telling the story. For example, economist are often interested in using regression models to explain the relationships of one set of economic parameters on another. Take for instance using inflation index and consumer price index to forecast borrow rates. The economists would be interested in building a model that can tell them that and x-amount increase in inflation will result in w*x-amount increase/decrease in the rate. Using predictor variables that are highly correlated with each other will most likely result in a model that “keeps changing” its story.
Let’s continue with our example of forecasting the borrow rate. Please note that in reality there may be no relationship between the borrow rate and inflation index or consumer price index. I am simply using these to illustrate the regression point. So, let’s imagine that inflation index (II) is correlated with the consumer price index (CPI) at 92%. Let’s also assume that we want to use the import tax rate (ITR) in the regression, as we believe that it is a factor in the inflation dynamics. Interestingly, ITR has no correlation with II and it correlates with CPI at 5%. We believe that the regression equation therefore is:
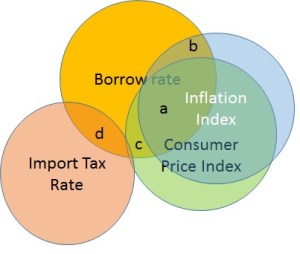
The LSR will estimate and . Both the magnitude and the sign of the coefficients will depend on how strongly the predictor variables correlated with each other. In [1] we can find a great visual explanation for this using Venn diagrams. Take a look at figure below. A Venn diagram is a good way to show to what extend CPI and II can predict the rate. There is a substantial overlap between CPI and the rate and the II and the rate (~ 40%?). However, because CPI and II overlap themselves, the only credit each predictor gets assigned is the unique non-overlapping contribution. The unique contribution of CPI will be the size of area c. The unique contribution of II will be the area b. The area a will be “lost” to the standard error (see Note a below).
Figure 1. Collinearity as overlap in Venn diagrams.
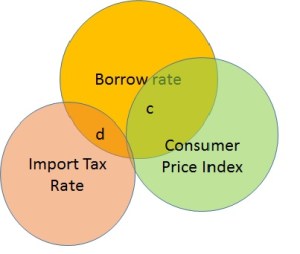
How does this make our regression solution unstable? Imagine we decide not to use II. The Venn diagram now looks like Figure 2. The regression coefficient of CPI will blow-up to the full credit it deserves. This will change our previous story about how CPI explains the borrow rate. If I were to remove the ITR instead, the coefficients of II and CPI would not have changed significantly. Thus in presence of multicollinearity among the predictor variables, neither do we get a stable solution, nor can we use it to properly interpret the underlying relationships.
Figure 2. Venn diagram for Collinearity without II.
Are you Sitting Comfortably?
Which chair would you rather sit on? Me too. In [2] we can find another great visual insight into how multicollinearity impacts the stability of LSR.
A scatter plot of two uncorrelated variables looks like a sea of data points. A scatter plot of two highly correlated variables looks more like a straight line. A regression solution will fit a hyperplane through the data points and the more spread-out the data points are, the more stable is the shape and direction of the best fit hyperplane. If, however, the data is align in a straight line, the best fit plane can be at any angle, depending on which target point it has to go through.
Figure 3. Fitting a hyperplane through data points.
Figure 3 above shows that the uncorrelated data points act like anchors for the left hyperplane. In case of strongly correlated II and CPI where the data points are in a line, there are no anchors for the sides and corners of the right plane, and it will “tilt” into the direction of whichever BR point it has to go through.
Summary and Conclusion
I hope you have found this visual insight into the impact of multi/collinearity revealing. I definitely did. To conclude, the presence of multicollinearity among the predictor variables in the least squares standard multiple regression does not invalidate the predictions generated by the fitted model. However, the stability of the model and its usefulness in telling the story about the model parameters is compromised.
References:
[1]. Using Multivariate Statistics. Barbara Tabachnick and Linda Fidell. 2013, 6th edition. Pearson.
[2]. Online Statistics course STATS501. https://onlinecourses.science.psu.edu/stat501/
Notes:
(a) In practice, the total coefficients weight assigned to CPI and II will approximately reflect the entire a+b+c area. If CPI and II both have the same real contributions, the individual weights assigned by the regression may depend on the order of data columns (i.e. does CPI appear before II) that is used to fit regression model, with the first predictor receiving the greatest weight. By “lost to standard error” I mean the dependence on these random factors like order, as well as an overall increase in the standard error of CPI and II regression coefficients.
I have recently attended a PyData meetup in London where Nicolas Radcliffe gave a nice talk on the concept of Test-Driven Data Analysis (TDDA). Here is a link to the slides that he presented.
Essentially, the idea behind TDDA is born from a well-known idea of Test Driven Software Development (TDSD or simply TDD). In TDSD, the test cases are written before the core code. This is often done to avoid developing solutions for specific scenarios and missing the edge cases. Take for example division. Everyone (hopefully) provides for division by zero, but what about integer division when a floating number is expected? How many times have you been caught out by this in a dynamic programming language like Python, staring at the code and wondering why every number comes out as zero? Developers who use TDSD specify at the start what the code should behave like and the constraints placed on the results.
Right now the practice of data science and data analysis very much lacks the structure of TDSD. I liked Nicolas’s 5th slide where he schematically shows the pillars of the data scientist’s workflow: trying, eyeballing and trying again until it makes sense. However, each stage of data analysis is prone to error. Starting from choosing the modelling approach down to interpretation of the results. Errors can be made in data pre-processing, model implementation, output gathering and even when plotting graphs. One of the main points of the talk was reproducible research. If every analysis is wrapped in a verification procedure that ensures that the same outputs are produced for the same inputs, then analysis bugs can be greatly reduced.
Another strong point of the talk was about using constraints. Much of the test-driven software development relies on constraints placed on the allowed inputs&outputs. In the data analysis, such constraints can be placed on data types, data value ranges, legality of duplicates, or even statistical and distributional properties. For example, can a value of an insurance claim be negative? What about a negative correlation between the insurance costs and the values of the claim?
I am hugely in favor of everything that makes software development more disciplined and the final result more robust. Thus you can see why I liked Nicolas’s ideas so much. It made me think about how and where I can incorporate TDDA in my work. Let’s take the work horse of data science – the least squares (standard multiple) regression. Can TDDA safeguard from common mistakes of applying regression and interpreting its results? I think it can. The quality of regression analysis and the ability of reproducing and reusing the regression model results will depend on the following parameters, all of which can be the constraints of TDDA:
Inputs: number of input cases vs. the number of independent variables: too many or too few input cases can invalidate regression analysis. When the number of input variables is small compared to the number of independent variables (i.e. the attributes of regression), the regression converges on perfect but meaningless solution. Another possibility is that the variance-covariance matrix can be non-invertable. Alternatively, when one tries to fit regression to too much data, almost any amount of correlation between the dependent and the independent variable can become statistically significant. A large number of false positives is an unfortunate side-effect of big data used in the wrong way. A possible constraint can be a simple check if the number of cases is ≥ 50 + 8 * ‘# of independent variables’.
Inputs: presence of singularity and multicollinearity: two regression attributes are singular if one of them is redundant (e.g. age and year of birth). Multicolliniear attributes are highly correlated, and in the case of standard multiple regression (as opposed to the step-wise regression, for example), can significantly impact/reduce the regression coefficients.
Inputs: presence of outliers: everyone knows what outliers can do to the statistics like the mean and standard deviation. Likewise, outliers can significantly impact the coefficients of regressions. A constraint on outliers absence can be placed on the data.
Output: normality and linearity of residuals: if regression was performed on non-transformed data, the residuals should always be examined. Skewed residuals may point to absence of normality in the input data, and non-normal input data may invalidate your prediction intervals if regression model is used to make predictions. Non-linear residuals may indicate that the originally suggested linear relationship between the dependent and the independent variables is inaccurate. Absence of normality is often dealt with data transformations (e.g. taking square roots or logarithms). Non-linearity will require re-visiting the original model (e.g. squaring or cubing the attributes).
Output: homoscedasticity of residuals: the absence of homoscedasticity between the error and the predicted variable may occur if the response is related to some transformation of the dependent variable instead of its original form. In other words, the relationship of the two variables varies over time. For example, the relationship between age and income is very likely to have this non-linear shape, since income of young people varies less than income of people who are over forty. I should note that the presence of heteroscedasticity does not invalidate regression results, but it may weaken the strength of its interpretation. Again, data transformation can come to the rescue (e.g. taking the logarithm).
Here you go – we have come up with five constraints that can be placed on regression input and output to ensure robust data analysis. Luckily most analytical platforms like SAS or SPSS have built-in checks that flag when these constraints are not satisfied. But in case if you are playing with a regression tool from another package – watch out. There is no need to increase that figure of 90% (see slide # 10)…
This post is to introduce a new Python package samplepy. This package was written to simplify sampling tasks that so often creep-up in machine learning. The package implements Importance, Rejection and Metropolis-Hastings sampling algorithms.
samplepy has a very simple API. The package can be installed with pip by simply running pip install samplepy. Once installed, you can use it to sample from any univariate distribution as following (showing rejection sampling use):
from samplepy import Rejection
import matplotlib.pyplot as plt
import numpy as np
# define a unimodal function to sample under
f = lambda x: 2.0*np.exp(-2.0*x)
# instantiate Rejection sampling with f and required interval
rej = Rejection(f, [0.01, 3.0])
# create a sample of 10K points
sample = rej.sample(10000, 1)
# plot the original function and the created sample set
x = np.arange(0.01, 3.0, (3.0-0.01)/10000)
fx = f(x)
figure, axis = plt.subplots()
axis.hist(sample, normed=1, bins=40)
axis2 = axis.twinx()
axis2.plot(x, fx, 'g', label="f(x)=2.0*exp(-2*x)")
plt.legend(loc=1)
plt.show()
Sample from f(x)=2.0*exp(-2*x) over [0.01, 3.0]
The three sampling method (i.e. Rejection, Importance and MH) are quite different and will achieve slightly different results for the same function. Performance is another important difference factor, with Metropolis-Hastings probably being the slowest. Let’s compare how the three sampling algorithm deliver on a bi-modal univariate function:
from samplepy import Rejection, Importance, MH
import matplotlib.pyplot as plt
import numpy as np
f = lambda x: np.exp(-1.0*x**2)*(2.0+np.sin(5.0*x)+np.sin(2.0*x))
interval = [-3.0, 3.0]
rej = Rejection(f, interval) # instantiate Rejection sampling with f and interval
sample = rej.sample(10000, 1) # create a sample of 10K points
x = np.arange(interval[0], interval[1], (interval[1]-interval[0])/10000)
fx = f(x)
figure, axis = plt.subplots()
axis.hist(sample, normed=1, bins=40)
axis2 = axis.twinx()
axis2.plot(x, fx, 'g', label="Rejection")
plt.legend(loc=1)
plt.show()
mh = MH(f,interval)
sample = mh.sample(20000, 100, 1) # Make sure we have enough points in the sample!
figure, axis = plt.subplots()
axis.hist(sample, normed=1, bins=40)
axis2 = axis.twinx()
axis2.plot(x, fx, 'g', label="MH")
plt.legend(loc=1)
plt.show()
imp = Importance(f, interval)
sample = imp.sample(10000, 0.0001, 0.0010) # create a sample where essentially no extra importance is given to any quantile
figure, axis = plt.subplots()
axis.hist(sample, normed=1, bins=40)
axis2 = axis.twinx()
axis2.plot(x, fx, 'g', label="Importance")
plt.legend(loc=1)
plt.show()
Hopefully this gives you enough examples to get you started using samplepy!
This is the 2nd part of the tutorial on Hidden Markov models. In this post we will look at a possible implementation of the described algorithms and estimate model performance on Yahoo stock price time-series.
Implementation of HMM in Python
I am providing an example implementation on my GitHub space. Please note that all code is provided with a disclaimer that you are free to use it at your own risk. HMM.py contains the main implementation. There are a few things to point out in this file:
As is pointed out in the referenced document in part 1, and require to be scaled for longer observations since the product of probabilities quickly tends to zero, resulting in underflow. The code has a flag for scaling, and defaults to positive.
While testing out this model I noticed that initial assignment of and makes a big difference to the final solution. I am providing two possible assignments. One, as described in part 1, setting approximately to the same values, adding to 1. And two, using Dirichlet distribution to create non-uniform assignment that adds-up to 1. I’ve noticed that the former results in more meaningful model parameters.
You will notice a small hack in HMMBaumWelch method where I am setting to the maximum observation in . This is needed because not all observation sequences will contain all values (i.e. 0, 1, 2). And the transition and emission matrices are accessed as if all the values exist.
I am using yahoo_finance Python module to source the stock prices for Yahoo. It seems to work and is pretty easy to use. You should be able to download this module here.
HMM Model performance to predict Yahoo stock price move
On my github space, HMM_test.py contains a possible test example code. I am testing the model as following: train the model on a specified window of daily historical moves (e.g. 10 days) and using the model parameters determine the predicted current model state. Then, using the predicted state, determine the next likely state from :
prediction_state = np.argmax(a[path[-1],:])
The most likely emitted value from that state can be found as follows:
prediction = np.argmax(b[prediction_state,:])
I then compare the predicted move to the historical one. So, how did HMM do? Well, not so well. The model parameters are very sensitive to the convergence tolerance, initial assignment and, obviously the training time-window. Calculating accuracy ratio as the number of correctly predicted directions is pretty much around 50%-56% (tests on more recent data produce the higher accuracy in this range). Thus, we might as well be throwing a coin to make buy or sell predictions. It is possible that EOD price moves are not granular enough to provide a coherent market dynamic model.
This tutorial is on a Hidden Markov Model. What is a Hidden Markov Model and why is it hiding?
Can you see me?
I have split the tutorial in two parts. Part 1 will provide the background to the discrete HMMs. I will motivate the three main algorithms with an example of modeling stock price time-series. In part 2 I will demonstrate one way to implement the HMM and we will test the model by using it to predict the Yahoo stock price!
A Hidden Markov Model (HMM) is a statistical signal model. This short sentence is actually loaded with insight! A statistical model estimates parameters like mean and variance and class probability ratios from the data and uses these parameters to mimic what is going on in the data. A signal model is a model that attempts to describe some process that emits signals. Putting these two together we get a model that mimics a process by cooking-up some parametric form. Then we add “Markov”, which pretty much tells us to forget the distant past. And finally we add ‘hidden’, meaning that the source of the signal is never revealed. BTW, the later applies to many parametric models.
Setting up the Scene
HMM is trained on data that contains an observed sequence of signals (and optionally the corresponding states the signal generator was in when the signals were emitted). Once the HMM is trained, we can give it an unobserved signal sequence and ask:
How probable is that this sequence was emitted by this HMM? This would be useful for a problem like credit card fraud detection.
What is the most probable set of states the model was in when generating the sequence? This would be useful for a problem of time-series categorization and clustering.
It is remarkable that the model that can do so much was originally designed in the 1960-ies! Here we will discuss the 1-st order HMM, where only the current and the previous model states matter. Compare this, for example, with the nth-order HMM where the current and the previous n states are used. Here, by “matter” or “used” we will mean used in conditioning of states’ probabilities. For example, we will be asking about the probability of the HMM being in some state given that the previous state was . Such probabilities can be expressed in 2 dimensions as a state transition probability matrix. Let’s pick a concrete example. Let’s image that on the 4th of January 2016 we bought one share of Yahoo Inc. stock. Let’s say we paid $32.4 for the share. From then on we are monitoring the close-of-day price and calculating the profit and loss (PnL) that we could have realized if we sold the share on the day. The states of our PnL can be described qualitatively as being up, down or unchanged. Here being “up” means we would have generated a gain, while being down means losing money. The PnL states are observable and depend only on the stock price at the end of each new day. What generates this stock price? The stock price is generated by the market. The states of the market influence whether the price will go down or up. The states of the market can be inferred from the stock price, but are not directly observable. In other words they are hidden.
So far we have described the observed states of the stock price and the hidden states of the market. Let’s imagine for now that we have an oracle that tells us the probabilities of market state transitions. Generally the market can be described as being in bull or bear state. We will call these “buy” and “sell” states respectively. Table 1 shows that if the market is selling Yahoo stock, then there is a 70% chance that the market will continue to sell in the next time frame. We also see that if the market is in the buy state for Yahoo, there is a 42% chance that it will transition to selling next.
Table 1
Sell
Buy
Sell
0.70
0.30
Buy
0.42
0.58
The oracle has also provided us with the stock price changes probabilities per market state. Table 2 shows that if the market is selling Yahoo, there is an 80% chance that the stock price will drop below our purchase price of $32.4 and will result in negative PnL. We also see that if the market is buying Yahoo, then there is a 10% chance that the resulting stock price will not be different from our purchase price and the PnL is zero. As I said, let’s not worry about where these probabilities come from. It will become clear later on. Note that row probabilities add to 1.0
Table 2
Down
Up
Unchanged
Sell
0.80
0.15
0.05
Buy
0.25
0.65
0.10
It is February 10th 2016 and the Yahoo stock price closes at $27.1. If we were to sell the stock now we would have lost $5.3. Before becoming desperate we would like to know how probable it is that we are going to keep losing money for the next three days.
To put this in the HMM terminology, we would like to know the probability that the next three time-step sequence realised by the model will be {down, down, down} for t=1, 2, 3. This sequence of PnL states can be given a name . So far the HMM model includes the market states transition probability matrix (Table 1) and the PnL observations probability matrix for each state (Table 2). Let’s call the former A and the latter B. We need one more thing to complete our HMM specification – the probability of stock market starting in either sell or buy state. Intuitively, it should be clear that the initial market state probabilities can be inferred from what is happening in Yahoo stock market on the day. But, for the sake of keeping this example more general we are going to assign the initial state probabilities as . Thus we are treating each initial state as being equally likely. So, the market is selling and we are interested to find out . This is the probability to observe sequence given the current HMM parameterization. It is clear that sequence can occur under 2^3=8 different market state sequences. To solve the posed problem we need to take into account each state and all combinations of state transitions. The probability of this sequence being emitted by our HMM model is the sum over all possible state transitions and observing sequence values in each state.
Table 3
Sell, Sell, Sell
Sell, Sell, Buy
Sell, Buy, Sell
Sell, Buy, Buy
Buy, Sell, Sell
Buy, Buy, Sell
Buy, Sell, Buy
Buy, Buy, Buy
This gives rise to very long sum!
In total we need to consider 2*3*8=48 multiplications (there are 6 in each sum component and there are 8 sums). That is a lot and it grows very quickly. Please note that emission probability is tied to a state and can be re-written as a conditional probability of emitting an observation while in the state. If we perform this long calculation we will get . There is an almost 20% chance that the next three observations will be a PnL loss for us!
Oracle is No More
Neo Absorbs Fail
In the previous section we have gained some intuition about HMM parameters and some of the things the model can do for us. However, the model is hidden, so there is no access to oracle! The state and emission transition matrices we used to make projections must be learned from the data. The hidden nature of the model is inevitable, since in life we do not have access to the oracle. In life we have access to historical data/observations and a magic methods of “maximum likelihood estimation” (MLE) and Bayesian inference. The MLE essentially produces distributional parameters that maximize the probability of observing the data at hand (i.e. it gives you the parameters of the model that is most likely have had generated the data). The HMM has three parameters . A fully specified HMM should be able to do the following:
Given a sequence of observed values, provide us with a probability that this sequence was generated by the specified HMM. This can be re-phrased as the probability of the sequence occurring given the model. This is what we have calculated in the previous section.
Given a sequence of observed values, provide us with the sequence of states the HMM most likely has been in to generate such values sequence.
Given a sequence of observed values we should be able to adjust/correct our model parameters , and .
When looking at the three ‘should’, we can see that there is a degree of circular dependency. That is, we need the model to do steps 1 and 2, and we need the parameters to form the model in step 3. Where do we begin? There are three main algorithms that are part of the HMM to perform the above tasks. These are: the forward&backward algorithm that helps with the 1st problem, the Viterbi algorithm that helps to solve the 2nd problem, and the Baum-Welch algorithm that puts it all together and helps to train the HMM model. Let’s discuss them next.
Going Back and Forth
That long sum we performed to calculate grows exponentially in the number of states and observed values. The Forward and Backward algorithm is an optimization on the long sum. If you look back at the long sum, you should see that there are sum components that have the same sub-components in the product. For example,
appears twice. The HMM Forward and Backward (HMM FB) algorithm does not re-compute these, but stores the partial sums as a cache. There are states, discrete values that can be emitted from each of states and . There are observations in the considered sequence . The state transition matrix is , where is an individual entry and . The emission matrix is , where is an individual entry , and , is state at time t. For initial states we have . The problem of finding the probability of sequence given an HMM is . Formally this probability can be expressed as a sum:
HMM FB calculates this sum efficiently by storing the partial sum calculated up to time . HMM FB is defined as follows:
Start by initializing the “cache” , where .
Calculate over all remaining observation sequences and states the partial sums: , where and . Since at a single iteration we hold constant, this results in a trellis-like calculation along the columns of the transition matrix.
The probability is then given by . This is where we gather the individual states probabilities together.
The above is the Forward algorithm which requires only calculations. The algorithm moves forward. We can imagine an algorithm that performs similar calculation, but backwards, starting from the last observation in . Why do we need this? Is the Forward algorithm not enough? It is enough to solve the 1st poised problem. But it is not enough to solve the 3rd problem, as we will see later. So, let’s define the Backward algorithm now.
Start by initializing the end “cache” , for . This is an arbitrary assignment.
Calculate over all remaining observation sequences and states the partial sums (moving back to the start of the observation sequence): , where and . Since at a single iteration we hold constant, this results in a trellis-like calculation along the columns of the transition matrix. However, it is performed backwards in time.
The matrix also contains probabilities of observing sequence . However, the actual values in are different from those in because of the arbitrary assignment of to 1.
The State of the Affairs
We are now ready to solve the 2nd problem of the HMM – given the model and a sequence of observations, provide the sequence of states the model likely was in to generate such a sequence. Strictly speaking, we are after the optimal state sequence for the given . Optimal often means maximum of something. At each state and emission transitions there is a node that maximizes the probability of observing a value in a state. Let’s take a closer look at the and matrices we calculated for the example.
Example Alpha and Beta
I have circled the values that are maximum. All of these correspond to the Sell market state. Our HMM would have told us that the most likely market state sequence that produced was . Which makes sense. The HMM algorithm that solves the 2nd problem is called Viterbi Algorithm, named after its inventor Andrew Viterbi. The essence of Viterbi algorithm is what we have just done – find the path in the trellis that maximizes each node probability. It is a little bit more complex than just looking for the max, since we have to ensure that the path is valid (i.e. it is reachable in the specified HMM).
We are after the best state sequence for the given . The best state sequence maximizes the probability of the path. We will be taking the maximum over probabilities and storing the indices of states that result in the max.
Start by initializing the end “cache” , for . We also need to initialize to zero a variable used to track the index of the max node: .
Calculate over all remaining observation sequences and states the partial max and store away the index that delivers it: , where and .
Update the sequence of indices of the max nodes as: for j and t as above.
Termination (probability and state):
The optimal state sequence is given by the path: , for
Expect the Unexpected
And now what is left is the most interesting part of the HMM – how do we estimate the model parameters from the data? We will now describe the Baum-Welch Algorithm to solve this 3rd poised problem.
The reason we introduced the Backward Algorithm is to be able to express a probability of being in some state i at time t and moving to a state j at time t+1. Imagine again the probabilities trellis. Pick a model state node at time t, use the partial sums for the probability of reaching this node, trace to some next node j at time t+1, and use all the possible state and observation paths after that until T. This gives the probability of being in state and move to . The figure below graphically illustrates this point.
Starting in i and moving to j.
To make this transition into a proper probability, we need to scale it by all possible transitions in and . It can now be defined as follows:
So, is a probability of being in state i at time t and moving to state j at time t+1. It makes perfect sense as long as we have true estimates for , , and . We will come to these in a moment…
Summing across gives the probability of being in state i at time t under and : . Let’s look at an example to make things clear. Let’s consider . We will use the same and from Table 1 and Table 2. The learned for this observation sequence is shown below:
Alpha for O={0,1,1}
The (un-scaled) is shown below:
Beta for O={0,1,1}
So, what is ? It is (0.7619*0.30*0.65*0.176)/0.05336=49%, where the denominator is calculated for . The denominator is calculated across all i and j at , thus it is a normalizing factor. If we calculate and sum the two estimates together, we will get the expected number of transitions from state to . Note, we do transition between two time-steps, but not from the final time-step as it is absorbing. Similarly, the sum over , where gives the expected number of transitions from . It should now be easy to recognize that is the transition probability , and this is how we estimate it:
We can derive the update to in a similar fashion. The matrix stores probabilities of observing a value from in some state. For is the probability of observing symbol in state j. The update rule becomes:
stores the initial probabilities for each state. This parameter can be updated from the data as:
We now have the estimation/update rule for all parameters in . The Baum-Welch algorithm is the following:
Repeat until convergence:
Initialize to random values such that , and . It is important to ensure that row probabilities add up to 1 and probabilities are not uniform as this may result in convergence to a local maximum.
Compute , , and and .
Re-estimate , , and .
The convergence can be assessed as the maximum change achieved in values of and between two iterations. The authors of this algorithm have proved that either the initial model defines the optimal point of the likelihood function and , or the converged solution provides model parameters that are more likely for a given sequence of observations . The described algorithm is often called the expectation maximization algorithm and the observation sequence works like a pdf and is the “pooling” factor in the update of . I have described the discrete version of HMM, however there are continuous models that estimate a density from which the observation come from, rather than a discrete time-series.
I hope some of you may find this tutorial revealing and insightful. I will share the implementation of this HMM with you next time.
Reference: L.R.Rabiner. An introduction to Hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2):257-268, 1989.






![Sample from f(x)=2.0*exp(-2*x) over [0.01, 3.0]](https://codefying.com/wp-content/uploads/2016/10/rejfig_1.png?w=300&h=224)




 and
and 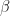 require to be scaled for longer observations since the product of probabilities quickly tends to zero, resulting in underflow. The code has a flag for scaling, and defaults to positive.
require to be scaled for longer observations since the product of probabilities quickly tends to zero, resulting in underflow. The code has a flag for scaling, and defaults to positive. and
and  makes a big difference to the final solution. I am providing two possible assignments. One, as described in part 1, setting approximately to the same values, adding to 1. And two, using Dirichlet distribution to create non-uniform assignment that adds-up to 1. I’ve noticed that the former results in more meaningful model parameters.
makes a big difference to the final solution. I am providing two possible assignments. One, as described in part 1, setting approximately to the same values, adding to 1. And two, using Dirichlet distribution to create non-uniform assignment that adds-up to 1. I’ve noticed that the former results in more meaningful model parameters. to the maximum observation in
to the maximum observation in  . This is needed because not all observation sequences will contain all values (i.e. 0, 1, 2). And the transition and emission matrices are accessed as if all the values exist.
. This is needed because not all observation sequences will contain all values (i.e. 0, 1, 2). And the transition and emission matrices are accessed as if all the values exist. :
: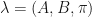 are very sensitive to the convergence tolerance, initial assignment and, obviously the training time-window. Calculating accuracy ratio as the number of correctly predicted directions is pretty much around 50%-56% (tests on more recent data produce the higher accuracy in this range). Thus, we might as well be throwing a coin to make buy or sell predictions. It is possible that EOD price moves are not granular enough to provide a coherent market dynamic model.
are very sensitive to the convergence tolerance, initial assignment and, obviously the training time-window. Calculating accuracy ratio as the number of correctly predicted directions is pretty much around 50%-56% (tests on more recent data produce the higher accuracy in this range). Thus, we might as well be throwing a coin to make buy or sell predictions. It is possible that EOD price moves are not granular enough to provide a coherent market dynamic model.
 given that the previous state was
given that the previous state was 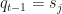 . Such probabilities can be expressed in 2 dimensions as a state transition probability matrix. Let’s pick a concrete example. Let’s image that on the 4th of January 2016 we bought one share of Yahoo Inc. stock. Let’s say we paid $32.4 for the share. From then on we are monitoring the close-of-day price and calculating the profit and loss (PnL) that we could have realized if we sold the share on the day. The states of our PnL can be described qualitatively as being up, down or unchanged. Here being “up” means we would have generated a gain, while being down means losing money. The PnL states are observable and depend only on the stock price at the end of each new day. What generates this stock price? The stock price is generated by the market. The states of the market influence whether the price will go down or up. The states of the market can be inferred from the stock price, but are not directly observable. In other words they are hidden.
. Such probabilities can be expressed in 2 dimensions as a state transition probability matrix. Let’s pick a concrete example. Let’s image that on the 4th of January 2016 we bought one share of Yahoo Inc. stock. Let’s say we paid $32.4 for the share. From then on we are monitoring the close-of-day price and calculating the profit and loss (PnL) that we could have realized if we sold the share on the day. The states of our PnL can be described qualitatively as being up, down or unchanged. Here being “up” means we would have generated a gain, while being down means losing money. The PnL states are observable and depend only on the stock price at the end of each new day. What generates this stock price? The stock price is generated by the market. The states of the market influence whether the price will go down or up. The states of the market can be inferred from the stock price, but are not directly observable. In other words they are hidden.
 . So far the HMM model includes the market states transition probability matrix (Table 1) and the PnL observations probability matrix for each state (Table 2). Let’s call the former A and the latter B. We need one more thing to complete our HMM specification – the probability of stock market starting in either sell or buy state. Intuitively, it should be clear that the initial market state probabilities can be inferred from what is happening in Yahoo stock market on the day. But, for the sake of keeping this example more general we are going to assign the initial state probabilities as
. So far the HMM model includes the market states transition probability matrix (Table 1) and the PnL observations probability matrix for each state (Table 2). Let’s call the former A and the latter B. We need one more thing to complete our HMM specification – the probability of stock market starting in either sell or buy state. Intuitively, it should be clear that the initial market state probabilities can be inferred from what is happening in Yahoo stock market on the day. But, for the sake of keeping this example more general we are going to assign the initial state probabilities as 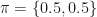 . Thus we are treating each initial state as being equally likely. So, the market is selling and we are interested to find out
. Thus we are treating each initial state as being equally likely. So, the market is selling and we are interested to find out  . This is the probability to observe sequence
. This is the probability to observe sequence 
 . There is an almost 20% chance that the next three observations will be a PnL loss for us!
. There is an almost 20% chance that the next three observations will be a PnL loss for us!
 . A fully specified HMM should be able to do the following:
. A fully specified HMM should be able to do the following: ,
, 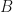 and
and  .
. grows exponentially in the number of states and observed values. The Forward and Backward algorithm is an optimization on the long sum. If you look back at the long sum, you should see that there are sum components that have the same sub-components in the product. For example,
grows exponentially in the number of states and observed values. The Forward and Backward algorithm is an optimization on the long sum. If you look back at the long sum, you should see that there are sum components that have the same sub-components in the product. For example,
 states,
states,  states and
states and 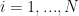 . There are
. There are 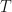 observations in the considered sequence
observations in the considered sequence 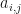 is an individual entry and
is an individual entry and  . The emission matrix is
. The emission matrix is 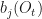 is an individual entry
is an individual entry 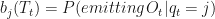 , and
, and  ,
,  is state at time t. For initial states we have
is state at time t. For initial states we have  . The problem of finding the probability of sequence
. The problem of finding the probability of sequence 
 . HMM FB is defined as follows:
. HMM FB is defined as follows:  , where
, where  .
.![\alpha_{t+1}(j)=\big[\sum_{j=1}^{N} \alpha_{ij}\big] b_{j}(O_{t+1})](https://s0.wp.com/latex.php?latex=%5Calpha_%7Bt%2B1%7D%28j%29%3D%5Cbig%5B%5Csum_%7Bj%3D1%7D%5E%7BN%7D+%5Calpha_%7Bij%7D%5Cbig%5D+b_%7Bj%7D%28O_%7Bt%2B1%7D%29&bg=ffffff&fg=111111&s=0&c=20201002) , where
, where  and
and  . Since at a single iteration we hold
. Since at a single iteration we hold 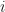 constant, this results in a trellis-like calculation along the columns of the transition matrix.
constant, this results in a trellis-like calculation along the columns of the transition matrix.  . This is where we gather the individual states probabilities together.
. This is where we gather the individual states probabilities together. calculations. The algorithm moves forward. We can imagine an algorithm that performs similar calculation, but backwards, starting from the last observation in
calculations. The algorithm moves forward. We can imagine an algorithm that performs similar calculation, but backwards, starting from the last observation in 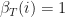 , for
, for  , where
, where  and
and 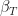 to 1.
to 1.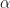 and
and 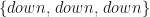 example.
example.
 . Which makes sense. The HMM algorithm that solves the 2nd problem is called Viterbi Algorithm, named after its inventor Andrew Viterbi. The essence of Viterbi algorithm is what we have just done – find the path in the trellis that maximizes each node probability. It is a little bit more complex than just looking for the max, since we have to ensure that the path is valid (i.e. it is reachable in the specified HMM).
. Which makes sense. The HMM algorithm that solves the 2nd problem is called Viterbi Algorithm, named after its inventor Andrew Viterbi. The essence of Viterbi algorithm is what we have just done – find the path in the trellis that maximizes each node probability. It is a little bit more complex than just looking for the max, since we have to ensure that the path is valid (i.e. it is reachable in the specified HMM). for the given
for the given  , for
, for  .
.![\delta_{t}(j)=\max_{1\le i \le N} \small[ \delta_{t-1}(i)a_{ij}\small]b_{j}(O_{t})](https://s0.wp.com/latex.php?latex=%5Cdelta_%7Bt%7D%28j%29%3D%5Cmax_%7B1%5Cle+i+%5Cle+N%7D+%5Csmall%5B+%5Cdelta_%7Bt-1%7D%28i%29a_%7Bij%7D%5Csmall%5Db_%7Bj%7D%28O_%7Bt%7D%29&bg=ffffff&fg=111111&s=0&c=20201002) , where
, where  and
and ![\phi_{t}=argmax_{1 \le i \le N} \small[ \delta_{t-1}(i) a_{ij}\small]](https://s0.wp.com/latex.php?latex=%5Cphi_%7Bt%7D%3Dargmax_%7B1+%5Cle+i+%5Cle+N%7D+%5Csmall%5B+%5Cdelta_%7Bt-1%7D%28i%29+a_%7Bij%7D%5Csmall%5D&bg=ffffff&fg=111111&s=0&c=20201002) for j and t as above.
for j and t as above.![P*=\max_{1 \le i \le N} \small[\delta_{T}(i)\small]](https://s0.wp.com/latex.php?latex=P%2A%3D%5Cmax_%7B1+%5Cle+i+%5Cle+N%7D+%5Csmall%5B%5Cdelta_%7BT%7D%28i%29%5Csmall%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![q_{T}*=argmax_{1 \le i \le N} \small[\delta_{T}(i)\small]](https://s0.wp.com/latex.php?latex=q_%7BT%7D%2A%3Dargmax_%7B1+%5Cle+i+%5Cle+N%7D+%5Csmall%5B%5Cdelta_%7BT%7D%28i%29%5Csmall%5D&bg=ffffff&fg=111111&s=0&c=20201002)
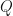 is given by the path:
is given by the path: , for
, for 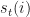 and move to
and move to 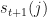 . The figure below graphically illustrates this point.
. The figure below graphically illustrates this point.
 and
and 
 is a probability of being in state i at time t and moving to state j at time t+1. It makes perfect sense as long as we have true estimates for
is a probability of being in state i at time t and moving to state j at time t+1. It makes perfect sense as long as we have true estimates for  gives the probability of being in state i at time t under
gives the probability of being in state i at time t under  . Let’s look at an example to make things clear. Let’s consider
. Let’s look at an example to make things clear. Let’s consider  . We will use the same
. We will use the same  learned for this observation sequence is shown below:
learned for this observation sequence is shown below:

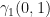 ? It is (0.7619*0.30*0.65*0.176)/0.05336=49%, where the denominator is calculated for
? It is (0.7619*0.30*0.65*0.176)/0.05336=49%, where the denominator is calculated for  . The denominator is calculated across all i and j at
. The denominator is calculated across all i and j at  and sum the two estimates together, we will get the expected number of transitions from state
and sum the two estimates together, we will get the expected number of transitions from state 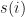 to
to  . Note, we do transition between two time-steps, but not from the final time-step as it is absorbing. Similarly, the sum over
. Note, we do transition between two time-steps, but not from the final time-step as it is absorbing. Similarly, the sum over  , where
, where  gives the expected number of transitions from
gives the expected number of transitions from  is the transition probability
is the transition probability 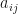 , and this is how we estimate it:
, and this is how we estimate it: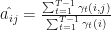
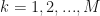
 is the probability of observing symbol
is the probability of observing symbol  in state j. The update rule becomes:
in state j. The update rule becomes:

 to random values such that
to random values such that  ,
, 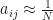 and
and 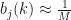 . It is important to ensure that row probabilities add up to 1 and probabilities are not uniform as this may result in convergence to a local maximum.
. It is important to ensure that row probabilities add up to 1 and probabilities are not uniform as this may result in convergence to a local maximum. ,
, 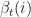 , and
, and 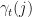 and
and  , or the converged solution provides model parameters that are more likely for a given sequence of observations
, or the converged solution provides model parameters that are more likely for a given sequence of observations 