
Greetings to my blog readers!
I have recently come across a puzzling code example in one book. Here is a snapshot of the code:
public interface ITwoFactorPayoff
{ // The unambiguous specification of two-factor payoff contracts
// This interface can be specialized to various underlyings
double payoff(double factorI1, double factorII);
}
public abstract class MultiAssetPayoffStrategy: ITwoFactorPayoff
{
public abstract double payoff(double S1, double S2);
}
Can you see why I was puzzled? The web is full of advice for when to choose abstract class vs. interface and the other way around. Take for example, this MSDN link or this stackoverflow Q&A. Anyone who is not lazy has written something about this already. However, a discussion on when one would want to use both is somewhat lacking. And rightly so, you may say. The above code introduces a redundancy with no apparent benefit. Here, inheriting from MultiAssetPayoffStrategy class still requires to implement the payoff method. So, why not just use the interface? I would agree with you that the example is poorly designed (in spite of the fact that the book it comes from is an expensive one!). Nevertheless, it got me thinking – when would one actually want to have abstract classes implementing interfaces. Here are the reasons I have come up with. Would be interested to know if you can add anything to this.
Reason 1 – Tidy Code
This is the simplest reason, and the first one that came to my mind. Imagine you have 10 or more interfaces that, a class hierarchy you are working on requires to implement. That is, class A must implement interface1, interface2, …, interfaceN; class B also must implement these interfaces. In other words, a situation that looks like this:
public interface Interface1
{
void method_interface1();
}
public interface Interface2
{
void method_interface2();
}
...
public class A: Interface1, Interface2
{
void method_interface1() {...}
void method_interface2() {...}
...
}
public class B: Interface1, Interface2
{
void method_interface1() {...}
void method_interface2() {...}
...
}
A way to simplify the code is to introduce either another interface that inherits from all 10 interfaces or simply an abstract class that does the same. Then, class A and class B just need to inherit from a single abstract class or a single interface.
Reason 2 – Providing Default Implementation for Some but Not Other Members
An abstract class could provide a default behavior for some methods. I admit, this is different to the book’s example since that method is an abstract one. But we all know that an abstract class can have non-abstract methods. The derived class then has an option on which methods it needs to implement. Here is a simple example (note that default implementation is decorated as virtual):
namespace OOPDesign
{
public interface IPrice
{
double Price(double strike);
}
public interface IPrintPrice
{
void PrintPrice(double price);
}
public abstract class Pricer: IPrice, IPrintPrice
{
public abstract double Price(double strike);
public virtual void PrintPrice(double price)
{
Console.WriteLine(price);
}
}
internal sealed class OptionPricer: Pricer
{
public override double Price(double strike)
{
return strike + 15;
}
}
class EntryPoint
{
static void Main(string[] args)
{
double strike = 20;
OptionPricer op = new OptionPricer();
op.PrintPrice(op.Price(strike));
Console.ReadLine();
}
}
}
Reason 3 – Combining Class Hierarchy with Contracts
This is probably the most obvious reason for choosing abstract classes together with interfaces. An abstract class can serve as a design summary of what all derived classes should do. This can aid in implementing a well-known visitor pattern. To give some credit to the mentioned book, it eventually evolves the example code to be based on this design pattern. If you are not familiar with the visitor pattern, I suggest you google it. Below I am providing a C# implementation based on the Java example one can find in Wikipedia (although it is not a one-for-one translation, as I have simplified the code a bit). This visitor pattern example can be summed-up as follows. We start off with three contracts: 2 interfaces and one abstract class. The abstract class is here to tell all its concrete classes to implement one of the interfaces (the accept method). The other interface is for the “visiting” classes. These visiting classes don’t really know what they are visiting, as long as the concrete class can accept them (which is guaranteed since the concrete classes are of the parent type and implement the accept functionality.
namespace VisitorExample
{
public interface ICarElementVisitor
{
void visit(CarBodyPart part);
}
public interface ICarElement
{
void accept(ICarElementVisitor visitor);
}
public abstract class CarBodyPart: ICarElement
{
public abstract void accept(ICarElementVisitor visitor);
public abstract string Name { get; }
public abstract string Action { get; }
}
public sealed class Wheel: CarBodyPart
{
private string name;
private string action;
public Wheel(string name, string action)
{
this.name = name;
this.action = action;
}
public override void accept(ICarElementVisitor visitor)
{
visitor.visit(this);
}
public override string Name
{
get
{
return this.name; ;
}
}
public override string Action
{
get
{
return this.action; ;
}
}
}
public sealed class Engine : CarBodyPart
{
private string name;
private string action;
public Engine(string name, string action)
{
this.name = name;
this.action = action;
}
public override void accept(ICarElementVisitor visitor)
{
visitor.visit(this);
}
public override string Name
{
get
{
return this.name; ;
}
}
public override string Action
{
get
{
return this.action; ;
}
}
}
public sealed class Body : CarBodyPart
{
private string name;
private string action;
public Body(string name, string action)
{
this.name = name;
this.action = action;
}
public override void accept(ICarElementVisitor visitor)
{
visitor.visit(this);
}
public override string Name
{
get
{
return this.name; ;
}
}
public override string Action
{
get
{
return this.action; ;
}
}
}
public sealed class Car : CarBodyPart
{
ICarElement[] elements;
private string name;
private string action;
public Car()
{
this.name = "car";
this.action = "driving ";
this.elements = new ICarElement[]
{ new Wheel("front left wheel", "Kicking my "),
new Wheel("front right wheel", "Kicking my "),
new Wheel("back left wheel", "Kicking my ") ,
new Wheel("back right wheel", "Kicking my "),
new Body("Body", "Moving my "),
new Engine("Engine", "Starting my ")
};
}
public override void accept(ICarElementVisitor visitor)
{
foreach(ICarElement elem in elements)
{
elem.accept(visitor);
}
visitor.visit(this);
}
public override string Name
{
get
{
return this.name; ;
}
}
public override string Action
{
get
{
return this.action; ;
}
}
}
sealed class CarElementPrintVisitor:ICarElementVisitor
{
public void visit(CarBodyPart part)
{
Console.WriteLine("Visiting " + part.Name);
}
}
sealed class CarElementActionVisitor:ICarElementVisitor
{
public void visit(CarBodyPart part)
{
Console.WriteLine(part.Action + part.Name);
}
}
class EntryPoint
{
static void Main(string[] args)
{
ICarElement car = new Car();
car.accept(new CarElementPrintVisitor());
car.accept(new CarElementActionVisitor());
Console.ReadLine();
}
}
}
Conclusion
Sometimes you end up accepting what you never thought you could accept…
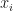 where
where  our task is to estimate
our task is to estimate  for
for  . Of course we may require to go outside of the range of our set of points, which would require extrapolation (or projection outside the known function values).
. Of course we may require to go outside of the range of our set of points, which would require extrapolation (or projection outside the known function values).
 and that
and that 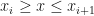 . We can re-write this expression as follows:
. We can re-write this expression as follows:
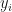 for
for 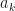 and
and  for
for  . Our linear interpolation is now taking a form of linear regression around
. Our linear interpolation is now taking a form of linear regression around ![[x_i, x_{i+1}]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+x_%7Bi%2B1%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002) . The cubic spline can be defined as:
. The cubic spline can be defined as: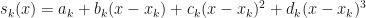
 and
and  coefficients, since
coefficients, since 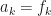 . Take
. Take  . The continuity condition (see P.R.Turner pg. 104) gives the following equalities:
. The continuity condition (see P.R.Turner pg. 104) gives the following equalities:
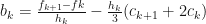
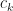 , we would be able to determine all the coefficients. After some re-arranging, it is possible to obtain:
, we would be able to determine all the coefficients. After some re-arranging, it is possible to obtain: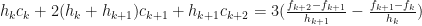
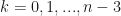 . This is a tridiagonal system of linear equations, which can be solved in a number of ways.
. This is a tridiagonal system of linear equations, which can be solved in a number of ways. . Using the above code we obtain the following results:
. Using the above code we obtain the following results:

