Greetings my blog readers!
This is my last post for 2015. All in all 2015 has been a good year. Many people from all over the world have read my posts, tried my code. Some even subscribed…
In this post I will do something rather simple – write an inverted index builder in C#. What is an inverted index? It is the simplest form of document indexing to allow for performing boolean queries on text data. For example, imagine we have several text files and we would like to find out which of them contain all or some of the search terms. We can group search terms using regular boolean AND and OR expressions.
To illustrate, let’s say we have two files, 1.xt and 2.txt. The two files contains the following:
file 1: one star is sparkling bright
file 2: two stars are sparkling even brighter
An inverted index on such data is built in four steps:
- Collect the documents.
- Tokenize the text by parsing each element.
- Perform linguistic pre-processing (e.g. removing punctuation, removing capitalization, etc.) to normalize the elements.
- Create an index in a form of a dictionary, where keys are the elements and the values are the documents that contain them.
It is really as simple as that. I am not going to code the normalization step as this would remove the main emphasis of this post. Instead, I will provide two simple extensions to allow for an AND and OR queries on the index.
So, given our short example files, how does the inverted index look like? Here is a visual example:

I use C# Dictionary to store such an index. The AND and OR are provided as extensions, and for a moment can handle only two keywords. It would be simple to remove this restriction by passing an array or a list to the extensions methods instead. In the end, the code is just an example of using LINQ (Intersect, Union and SelectMany). If you end up using this code, please add your own exceptions handling.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
namespace InvertedIndex
{
public static class Extensions
{
public static IEnumerable<string> And (this Dictionary<string, List<string>> index, string firstTerm, string secondTerm)
{
return(from d in index
where d.Key.Equals(firstTerm)
select d.Value).SelectMany(x=>x).Intersect
((from d in index
where d.Key.Equals(secondTerm)
select d.Value).SelectMany(x => x));
}
public static IEnumerable<string> Or(this Dictionary<string, List<string>> index, string firstTerm, string secondTerm)
{
return (from d in index
where d.Key.Equals(firstTerm) || d.Key.Equals(secondTerm)
select d.Value).SelectMany(x=>x).Distinct();
}
}
class EntryPoint
{
public static Dictionary<string, List<string>> invertedIndex;
static void Main(string[] args)
{
invertedIndex = new Dictionary<string, List<string>>();
string folder = "C:\\Users\\Elena\\Documents\\Visual Studio 2013\\Projects\\InvertedIndex\\Files\\";
foreach (string file in Directory.EnumerateFiles(folder, "*.txt"))
{
List<string> content = System.IO.File.ReadAllText(file).Split(' ').Distinct().ToList();
addToIndex(content, file.Replace(folder, ""));
}
var resAnd = invertedIndex.And("star", "sparkling");
var resOr = invertedIndex.Or("star", "sparkling");
Console.ReadLine();
}
private static void addToIndex(List<string> words, string document)
{
foreach (var word in words)
{
if (!invertedIndex.ContainsKey(word))
{
invertedIndex.Add(word, new List<string> { document });
}
else
{
invertedIndex[word].Add(document);
}
}
}
}
}
Enjoy and Happy New Year!
P.S. And here is the GitHub link: https://github.com/elena-sharova/Inverted-Index.git


![V=exp(-r\cdot \delta t)\cdot [p\cdot V_{u}+(1-p)\cdot V_{d}]](https://s0.wp.com/latex.php?latex=V%3Dexp%28-r%5Ccdot+%5Cdelta+t%29%5Ccdot+%5Bp%5Ccdot+V_%7Bu%7D%2B%281-p%29%5Ccdot+V_%7Bd%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002)


 , the yield
, the yield  equates the present value of the bond computed under a given set of rates. In other words:
equates the present value of the bond computed under a given set of rates. In other words:
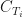 is a coupon paid out at time
is a coupon paid out at time 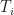 . Usually, one solves for
. Usually, one solves for 
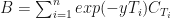 be the price(or present value) of the bond expressed via its yield. Then, taking
be the price(or present value) of the bond expressed via its yield. Then, taking  to represent interest rate, we have:
to represent interest rate, we have: and
and