Greetings, my blog readers!
It will be a safe assumption to make that people who read my blogs work with data. In finance, the data is often in form of asset prices or other market indicators like implied volatility. Analyzing price data often requires calculating returns (aka. moves). Very often we work with proportional returns or log returns. Proportional returns are calculated relative to the price level. For example, given any two historical prices 
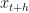
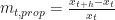
The above can be shortened as 

How do you know which type of return is appropriate for your data? The answer depends on the price dynamic and the simulation/analysis task at hand. Historical simulation, often used in Value-at-Risk (VaR), requires calculating PnL strip from some sensitivity and a set of historical returns. For example, a VaR model for foreign exchange options may be specified to take into account PnL impact from changes in implied volatility skew. Here, the PnL is historically simulated using sensitivities of a volatility curve or surface and historical implied volatility returns for some surface parameter, like low risk reversal. You have a choice in how to calculate the volatility returns. The right choice can be determined with a simple regression.
Essentially, we need to look for evidence of dependency of price returns on price levels. In FX, liquid options on G21 currency pairs do not exhibit such dependency, while emerging market pairs do. I have not been able to locate a free source of implied FX volatility, but I have found two instruments that are good enough to demonstrate the concept. CBOE LOVOL Index is a low volatility index and can be downloaded for free from Quandl. For this example I took the close of day prices from 2012-2017. After plotting 
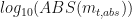
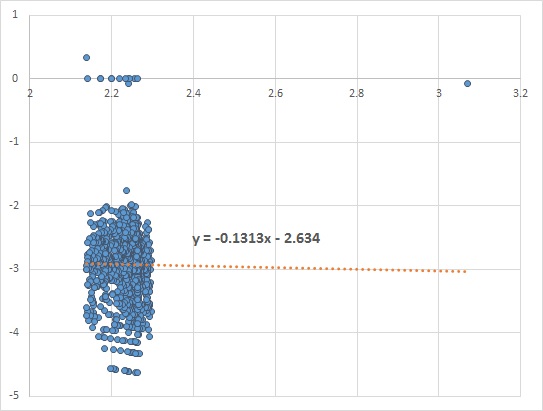
In the absence of dependency, absolute returns can be used, while proportional return are otherwise more appropriate. Take a look at a plot of VXMT CBOE Mid-term Volatility Index. The fitted linear line has a slope of approximately 1.7. Historical simulation of VXMT is calling for proportional rather than absolute price moves.