In C# all types can be split into reference and value types. This implies that there is a need for two different types of equality comparison mechanisms. Value and referential equality exist to allow us compare value and reference types. By default, value types use the value equality, and reference types rely on referential equality.
Before I proceed in comparing these equality types, let me try getting your attention with a simple example. Which of the two methods below would you rather have, if you were worried about run-time stability?
public static bool Equals1(double? a, double? b)
{
if (a == b)
return true;
else
return false;
}
public static bool Equals2(object a, object b)
{
if (a.Equals(b))
return true;
else
return false;
}
The acceptable answer is another question – it depends on what you are trying to achieve and the context of the task at hand. However, Equals2 is a small but a potentially dangerous function. If object a is null, we get a Null Reference Exception, as in the following example. The == comparison, on the other hand, will never fail so badly.
The reason for the behavior difference lies in the main difference between how == and object.Equals are implemented internally. The first is a static operator (or a function, if you like), and the second is a virtual method (remember you can override Equals?). Since dLeft is null, it cannot be de-referenced to call an Equals method on. The == operator, being a static function, resolves the type of dLeft at compilation. In our example, it is a boxed double (yes, nullable value types come at a cost). But even though we boxed our doubles, we get value type comparison in Equals1.
So, do we always have to check for null before calling Equals on them? Not always, as we can utilize the static helper object.Equals(object,object) instead. This method accepts two arguments and lets us avoid having to check for equality on a potentially null reference. Here is a much less dangerous Equals2 for you:
public static bool Equals2(object a, object b)
{
if (object.Equals(a,b))
return true;
else
return false;
}
To continue comparing ‘==’ with Equals, note that the latter is reflexive, meaning that two NaNs are equal according to Equals, and are different according to ‘==’. Other than execution speed, with value types ‘==’ and Equals behave the same. With reference types, the default behavior of Equals is value-type equality and with ‘==’ operator it is referential equality. This can be demonstrated with a simple example:
double left = 10;
double right = left;
double middle = 10;
if (right.Equals(middle))
Console.WriteLine("Same doubles");
else
Console.WriteLine("Diff doubles");
if (right==middle)
Console.WriteLine("Same doubles");
else
Console.WriteLine("Diff doubles");
object oLeft = 10;
object oRight = oLeft;
object oMiddle = 10;
if (oRight.Equals(oMiddle))
Console.WriteLine("Same objects");
else
Console.WriteLine("Diff objects");
if (oRight == oMiddle)
Console.WriteLine("Same objects");
else
Console.WriteLine("Diff objects");
The above will print that two variables are the same in the first 3 cases. In the last case, by default, ‘==’ for reference types performs referential equality comparison. Finally, if you are into numerical comparisons, I would recommend sticking with ‘==’ since it is faster than calling Equals or even CompareTo. For comparing monetary amounts, the difference between two doubles can be compared to some predefined numerical threshold (that is, still using ==).
I have previously covered delegates and events, but I’ve decided to go over the concept of delegates in C# once more. In addition, this time I will mention generic delegates.
So, let’s refresh – what is a delegate? A delegate is a type. It is a type that is designed to be compatible with methods. You may have come across someone comparing C# delegates with C++ function pointers. It is a fair functional comparison. That is, only a certain part of how C++ pointers behave and what they are used for is comparable with the C# delegates. As far as the internal representation – there is really almost nothing in common. The reason I bring up the function pointer is because I too think of delegates as being “like function pointers”. This makes it easier to understand their purpose and syntax. Let me reinforce this functional comparison with an example. Take the below declaration of a delegate:
public delegate T AnyMethod<T>(T input_param);
This declares a delegate that “can represent” any method that takes one parameter and returns one parameter. In other words, AnyMethod delegate is compatible with any method with a signature like that of this delegate. Since AnyMethod is generic, this gives us flexibility in what methods we can assign. Take a look at the below example code which was written to simply support this explanation. Given some appropriate type, AnyMethod can be assigned to a method that works with any parameter type.
using System;
namespace GenericDelegate
{
public delegate T AnyMethod<T>(T input_param);
class EntryLevel
{
static void Main(string[] args)
{
int i = 10;
string s = "any string";
AnyMethod<int> im = IntMethod; // this is the same as AnyMethod<int> im = new AnyMethod<int>(IntMethod);
AnyMethod<string> sm = StringMethod; // this is the same as AnyMethod<string> sm = new AnyMethod<string>(StringMethod);
im(i);
sm(s);
}
static int IntMethod(int int_param)
{
Console.WriteLine("Inside IntMethod with "+int_param.ToString());
return 0;
}
static string StringMethod(string string_param)
{
Console.WriteLine("Inside StringMethod with " + string_param);
return "void";
}
}
}
AnyMethod delegate can work with generic methods as well. I can easily replace my two static methods with a single generic one.
class EntryLevel
{
static void Main(string[] args)
{
int i = 10;
string s = "any string";
AnyMethod<int> im = TMethod; // same as AnyMethod<int> im = new AnyMethod<int>(TMethod);
AnyMethod<string> sm = TMethod; // same AnyMethod<string> sm = new AnyMethod<string>(TMethod);
im(i);
sm(s);
}
static T TMethod<T> (T t_param)
{
Console.WriteLine("Inside TMethod with " + t_param.ToString());
return t_param;
}
}
Remember I wrote that a delegate is a type. Note, I did not write that it is simply a method. Because it is not. Under the hood, for the delegate declaration on line 6, the compiler will be busy creating a real class (albeit a sealed one) that extends System.MultiCastDelegate class, has a constructor and three methods! I prefer not to bother with these details because they tend to confuse me. Instead, I will stick with the comfortable “types compatible with methods” definition. In fact, I like this definition so much that I will remove that delegate declaration entirely…And replace it with Func:
using System;
namespace GenericDelegate
{
class EntryLevel
{
static void Main(string[] args)
{
int i = 10;
string s = "any string";
Func<int, int> im = TMethod; // Func<int,int> im = new Func<int,int>(TMethod);
Func<string, string> sm = TMethod; // Func<string,string> sm = new Func<string,string>(TMethod);
im(i);
sm(s);
}
static T TMethod<T> (T t_param)
{
Console.WriteLine("Inside TMethod with " + t_param.ToString());
return t_param;
}
}
}
Much better! If you have never come across Func before, take a look at the reference source. You will see that Func is just another delegate (with an upper bound on its input parameters), but its definition has been hidden away. Action and Func were introduced in .Net 3.5. I believe they were added to support lambda expressions. However, both are very handy in covering up the unnecessary complexity and reinforcing my earlier analogy.
In one of my previous blogs I have touched upon the idea of programming to interfaces. I did not expect that the blog would be getting so many hits as it does. As far as writing maintainable loosely coupled code, I have a long way to go to become good at. Thus I’ve decided to investigate the most useful design patters to learn and introduce into the hobby and professional coding practices. And I am not going to start small…
One of the seriously misunderstood software design patterns is dependency injection. Many people like writing about it on their sites and blogs, but not many people do a decent job at describing it correctly. I am not claiming that I will now fix this for my blog readers. Instead, I will tel you that I am reading a fantastic book about it: Dependency Injection in .NET by Mark Seemann. So, if you are looking for a good material on this topic, please check out this recommendation.
My last post was on linear and cubic spline interpolation. The implementation can be improved, since I’ve hard-coded at least one inflexible dependency: outputting the results to the console screen. Anyone who wishes to use my example code without using the console screen (e.g. writing to a file instead) would need to rewrite at least twelve lines of code! We can definitely improve upon this by decoupling the console writer and substituting a generic class that is ‘injected‘ with the user-specified writer through a constructor (aka constructor injection).
To begin with, I made a small change to the Tridiagonal class and removed console-based output. The Solve method now throws ArgumentException whenever passed matrix is not square or something else went wrong. I then made a similar change to the extensions. After all, it is not a good idea to tie extensions to a specific output class like Console. The LinearInterpolation and CubicSplineInterpolation classes now have private constructors. The basic checks on user input is now done by the initializing methods, which could have been defined as properties. Also, the interpolating classes do not display any messages when something goes wrong. Instead, they throw appropriate exceptions, which the calling method will deal with. Finally, I have added a new UserOutput namespace which defines an interface and a very generic class that will work with any concrete implementation of Write method declared by the interface:
The concrete implementation is another class defined as:
internal class ConsoleWriter : UserOutput.IWriter
{
public void Write(string message)
{
Console.WriteLine(message);
}
}
The Main method creates an instance of the IWriter interface and sets it to the ConsoleWriter. The linear and cubic spline interpolations are called through the IInterpolate interface which they both define. We no longer need two separate instances of each class. The full code can be downloaded here as a pdf file.
In this post on numerical methods I will share with you the theoretical background and the implementation of the two types of interpolations: linear and natural cubic spline. These interpolations are often used within the financial industry. For example, discount rates for some maturity for which there is no point on an yield curve is often interpolated using cubic spline interpolation. Another example can be in risk management, like a position’s Value-at-Risk calculation obtained from a partial or a 2-dimensional revaluation grid.
Linear Interpolation
Let’s begin with the simplest method – linear interpolation. The idea is that we are given a set of numerical points and function values at these points. The task is to use the given set and approximate the function’s value at some different points. That is, given where our task is to estimate for . Of course we may require to go outside of the range of our set of points, which would require extrapolation (or projection outside the known function values).
Almost all interpolation techniques are based around the concept of function approximation. Mathematically, the backbone is simple:
The above expression tells us that the value of the function we are approximating at point x will be around and that . We can re-write this expression as follows:
where we have substituted for and for . Our linear interpolation is now taking a form of linear regression around .
Linear interpolation is the most basic type of interpolations. It works remarkably well for smooth functions with sufficient number of points. However, because it is such a basic method, interpolating more complex functions requires a little bit more work.
Cubic Spline Interpolation
In what follows I am going to borrow a few formulations from a very good book: Guide to Scientific Computing by P.R.Turner. The idea of a spline interpolation is to extend the single polynomial of linear interpolation to higher degrees. But unlike with piece-wise polynomials, the higher degree polynomials constructed by the cubic spline are different in each interval . The cubic spline can be defined as:
If you compare the above expression with the linear interpolation, you will see that we have added two terms to the rhs. It is these extra terms that should allow us achieve greater precision. There are certain requirements placed on s. These are: it must be continuous, and its first and second derivatives must exist. We only need to determine and coefficients, since . Take . The continuity condition (see P.R.Turner pg. 104) gives the following equalities:
Thus, if we had the values for , we would be able to determine all the coefficients. After some re-arranging, it is possible to obtain:
for . This is a tridiagonal system of linear equations, which can be solved in a number of ways.
Let’s now look at how we can implement the linear and cubic spline interpolation in C#.
Implementing Linear and Cubic Spline Interpolation in C#
The code is broken into five regions. Tridiagonal Matrix region defines a Tridiagonal class to solve a system of linear equations. The Extensions regions defines a few extensions to allows for matrix manipulations. The Foundation region is where the parent Interpolation class is defined. Both, Linear and Cubic Spline Interpolations classes inherit from it.
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace TridiagonalMatrix
{
#region TRIDIAGONAL_MATRIX
// solves a Tridiagonal Matrix using Thomas algorithm
public sealed class Tridiagonal
{
public double[] Solve(double[,] matrix, double[] d)
{
int rows = matrix.GetLength(0);
int cols = matrix.GetLength(1);
int len = d.Length;
// this must be a square matrix
if (rows == cols && rows == len)
{
double[] b = new double[rows];
double[] a = new double[rows];
double[] c = new double[rows];
// decompose the matrix into its tri-diagonal components
for (int i = 0; i < rows; i++)
{
for (int j=0; j<cols; j++)
{
if (i == j)
b[i] = matrix[i, j];
else if (i == (j - 1))
c[i] = matrix[i, j];
else if (i == (j + 1))
a[i] = matrix[i, j];
}
}
try
{
c[0] = c[0] / b[0];
d[0] = d[0] / b[0];
for (int i = 1; i < len - 1; i++)
{
c[i] = c[i] / (b[i] - a[i] * c[i - 1]);
d[i] = (d[i] - a[i] * d[i - 1]) / (b[i] - a[i] * c[i - 1]);
}
d[len - 1] = (d[len - 1] - a[len - 1] * d[len - 2]) / (b[len - 1] - a[len - 1] * c[len - 2]);
// back-substitution step
for (int i = (len - 1); i-- > 0; )
{
d[i] = d[i] - c[i] * d[i + 1];
}
return d;
}
catch(DivideByZeroException)
{
Console.WriteLine("Division by zero was attempted. Most likely reason is that ");
Console.WriteLine("the tridiagonal matrix condition ||(b*i)||>||(a*i)+(c*i)|| is not satisified.");
return null;
}
}
else
{
Console.WriteLine("Error: the matrix must be square. The vector must be the same size as the matrix length.");
return null;
}
}
}
#endregion
}
namespace BasicInterpolation
{
#region EXTENSIONS
public static class Extensions
{
// returns a list sorted in ascending order
public static List<T> SortedList<T>(this T[] array)
{
List<T> l = array.ToList();
l.Sort();
return l;
}
// returns a difference between consecutive elements of an array
public static double[] Diff(this double[] array)
{
int len = array.Length - 1;
double[] diffsArray = new double[len];
for (int i = 1; i <= len;i++)
{
diffsArray[i - 1] = array[i] - array[i - 1];
}
return diffsArray;
}
// scaled an array by another array of doubles
public static double[] Scale(this double[] array, double[] scalor, bool mult=true)
{
int len = array.Length;
double[] scaledArray = new double[len];
if (mult)
{
for (int i = 0; i < len; i++)
{
scaledArray[i] = array[i] * scalor[i];
}
}
else
{
for (int i = 0; i < len; i++)
{
if (scalor[i] != 0)
{
scaledArray[i] = array[i] / scalor[i];
}
else
{
// basic fix to prevent division by zero
scalor[i] = 0.00001;
scaledArray[i] = array[i] / scalor[i];
}
}
}
return scaledArray;
}
public static double[,] Diag(this double[,] matrix, double[] diagVals)
{
int rows = matrix.GetLength(0);
int cols = matrix.GetLength(1);
// the matrix has to be scare
if (rows==cols)
{
double[,] diagMatrix = new double[rows, cols];
int k = 0;
for (int i = 0; i < rows; i++)
for (int j = 0; j < cols; j++ )
{
if(i==j)
{
diagMatrix[i, j] = diagVals[k];
k++;
}
else
{
diagMatrix[i, j] = 0;
}
}
return diagMatrix;
}
else
{
Console.WriteLine("Diag should be used on square matrix only.");
return null;
}
}
}
#endregion
#region FOUNDATION
internal interface IInterpolate
{
double? Interpolate( double p);
}
internal abstract class Interpolation: IInterpolate
{
public Interpolation(double[] _x, double[] _y)
{
int xLength = _x.Length;
if (xLength == _y.Length && xLength > 1 && _x.Distinct().Count() == xLength)
{
x = _x;
y = _y;
}
}
// cubic spline relies on the abscissa values to be sorted
public Interpolation(double[] _x, double[] _y, bool checkSorted=true)
{
int xLength = _x.Length;
if (checkSorted)
{
if (xLength == _y.Length && xLength > 1 && _x.Distinct().Count() == xLength && Enumerable.SequenceEqual(_x.SortedList(),_x.ToList()))
{
x = _x;
y = _y;
}
}
else
{
if (xLength == _y.Length && xLength > 1 && _x.Distinct().Count() == xLength)
{
x = _x;
y = _y;
}
}
}
public double[] X
{
get
{
return x;
}
}
public double[] Y
{
get
{
return y;
}
}
public abstract double? Interpolate(double p);
private double[] x;
private double[] y;
}
#endregion
#region LINEAR
internal sealed class LinearInterpolation: Interpolation
{
public LinearInterpolation(double[] _x, double [] _y):base(_x,_y)
{
len = X.Length;
if (len > 1)
{
Console.WriteLine("Successfully set abscissa and ordinate.");
baseset = true;
// make a copy of X as a list for later use
lX = X.ToList();
}
else
Console.WriteLine("Ensure x and y are the same length and have at least 2 elements. All x values must be unique.");
}
public override double? Interpolate(double p)
{
if (baseset)
{
double? result = null;
double Rx;
try
{
// point p may be outside abscissa's range
// if it is, we return null
Rx = X.First(s => s >= p);
}
catch(ArgumentNullException)
{
return null;
}
// at this stage we know that Rx contains a valid value
// find the index of the value close to the point required to be interpolated for
int i = lX.IndexOf(Rx);
// provide for index not found and lower and upper tabulated bounds
if (i==-1)
return null;
if (i== len-1 && X[i]==p)
return Y[len - 1];
if (i == 0)
return Y[0];
// linearly interpolate between two adjacent points
double h = (X[i] - X[i - 1]);
double A = (X[i] - p) / h;
double B = (p - X[i - 1]) / h;
result = Y[i - 1] * A + Y[i] * B;
return result;
}
else
{
return null;
}
}
private bool baseset = false;
private int len;
private List<double> lX;
}
#endregion
#region CUBIC_SPLINE
internal sealed class CubicSplineInterpolation:Interpolation
{
public CubicSplineInterpolation(double[] _x, double[] _y): base(_x, _y, true)
{
len = X.Length;
if (len > 1)
{
Console.WriteLine("Successfully set abscissa and ordinate.");
baseset = true;
// make a copy of X as a list for later use
lX = X.ToList();
}
else
Console.WriteLine("Ensure x and y are the same length and have at least 2 elements. All x values must be unique. X-values must be in ascending order.");
}
public override double? Interpolate(double p)
{
if (baseset)
{
double? result = 0;
int N = len - 1;
double[] h = X.Diff();
double[] D = Y.Diff().Scale(h, false);
double[] s = Enumerable.Repeat(3.0, D.Length).ToArray();
double[] dD3 = D.Diff().Scale(s);
double[] a = Y;
// generate tridiagonal system
double[,] H = new double[N-1, N-1];
double[] diagVals = new double[N-1];
for (int i=1; i<N;i++)
{
diagVals[i-1] = 2 * (h[i-1] + h[i]);
}
H = H.Diag(diagVals);
// H can be null if non-square matrix is passed
if (H != null)
{
for (int i = 0; i < N - 2; i++)
{
H[i, i + 1] = h[i + 1];
H[i + 1, i] = h[i + 1];
}
double[] c = new double[N + 2];
c = Enumerable.Repeat(0.0, N + 1).ToArray();
// solve tridiagonal matrix
TridiagonalMatrix.Tridiagonal le = new TridiagonalMatrix.Tridiagonal();
double[] solution = le.Solve(H, dD3);
for (int i = 1; i < N;i++ )
{
c[i] = solution[i - 1];
}
double[] b = new double[N];
double[] d = new double[N];
for (int i = 0; i < N; i++ )
{
b[i] = D[i] - (h[i] * (c[i + 1] + 2.0 * c[i])) / 3.0;
d[i] = (c[i + 1] - c[i]) / (3.0 * h[i]);
}
double Rx;
try
{
// point p may be outside abscissa's range
// if it is, we return null
Rx = X.First(m => m >= p);
}
catch
{
return null;
}
// at this stage we know that Rx contains a valid value
// find the index of the value close to the point required to be interpolated for
int iRx = lX.IndexOf(Rx);
if (iRx == -1)
return null;
if (iRx == len - 1 && X[iRx] == p)
return Y[len - 1];
if (iRx == 0)
return Y[0];
iRx = lX.IndexOf(Rx)-1;
Rx = p - X[iRx];
result = a[iRx] + Rx * (b[iRx] + Rx * (c[iRx] + Rx * d[iRx]));
return result;
}
else
{
return null;
}
}
else
return null;
}
private bool baseset = false;
private int len;
private List<double> lX;
}
#endregion
class EntryPoint
{
static void Main(string[] args)
{
// code relies on abscissa values to be sorted
// there is a check for this condition, but no fix
// f(x) = 1/(1+x^2)*sin(x)
double[] ex = { -5, -3, -2, -1, 0, 1, 2, 3, 5};
double[] ey = { 0.036882, -0.01411, -0.18186, -0.42074, 0, 0.420735, 0.181859, 0.014112, -0.03688};
double[] p = {-5,-4.5,-4,-3.5,-3.2,-3,-2.8,-2.1,-1.5,-1,-0.8,0,0.65,1,1.3,1.9,2.6,3.1,3.5,4,4.5,5 };
LinearInterpolation LI = new LinearInterpolation(ex, ey);
CubicSplineInterpolation CS = new CubicSplineInterpolation(ex, ey);
Console.WriteLine("Linear Interpolation:");
foreach (double pp in p)
{
Console.Write(LI.Interpolate(pp).ToString()+", ");
}
Console.WriteLine("Cubic Spline Interpolation:");
foreach (double pp in p)
{
Console.WriteLine(CS.Interpolate(pp).ToString());
}
Console.ReadLine();
}
}
}
Note that I wrote a console application, and this is the reason for throwing as few exceptions as possible. Like with all the code on my blog – please feel free to take it and modify as you wish. It is now time to compare performance of linear and cubic spline interpolations on a test function: . Using the above code we obtain the following results:
The first programming language I could claim to be proficient at was C. Then, it was C++. Thus I would say that I am a ‘low-level’ programmer at heart, and I like to think about efficient memory consumption. What I am getting at is this – I do spent time thinking about the data type to use for an entity I need to encode, and I have not swore off structs yet. In C# a struct is a value type and value types are meant to be immutable. This means that, by default, they do not have interfaces that would allow the instance fields to be modified. Value types reside on the thread’s stack, and reference types reside on the heap managed by the garbage collector. The main advantage of using the stack for declaring variables is speed. Unlike with the heap allocation, we only need to update the stack pointer with a push or pop instruction. Finally, the stack variables’ life-time is easily determined by the scope of the program.
Structs, being the most advanced of the value types in C#, are very useful. However, sometimes it is difficult to decide between a class and a struct. Here is a concise guidance from Microsoft on when to prefer one type over another. The rule of thumb seems to be that if the type is small and should be immutable by design, then structs should be preferred over classes. We have now come to the main topic of this post, which is on how an interface implemented on a value type can affect its immutability. The idea behind the following code samples is not originally mine. I have borrowed it (and modified slightly) from J.Richter’s CLR via C#, 4th edition (part 2, Designing Types). Take a look at the short program below. Can you guess what its output is?
using System;
using System.Collections.Generic;
namespace BoxedValueTypesWithInterfaces
{
internal struct Coordinate
{
public Coordinate(int _x, int _y, int _z)
{
x = _x;
y = _y;
z = _z;
}
public void UpdateCoordinate(int _x, int _y, int _z)
{
x = _x;
y = _y;
z = _z;
}
public override string ToString()
{
return String.Format("({0},{1},{2})", x.ToString(), y.ToString(), z.ToString());
}
private int x;
private int y;
private int z;
}
class EntryPoint
{
static void Main(string[] args)
{
Coordinate myCoordinate = new Coordinate(0, 0, 0);
//no boxing because we overode ToString()
Console.WriteLine("Current position is " + myCoordinate.ToString());
myCoordinate.UpdateCoordinate(1, 2, 3);
Console.WriteLine("New position is " + myCoordinate.ToString());
//myCoordinate is boxed here
Object o = myCoordinate;
Console.WriteLine("Current position is " + o.ToString());
((Coordinate)o).UpdateCoordinate(2, 3, 4);
Console.WriteLine("New position is " + o.ToString());
Console.ReadLine();
}
}
}
The most interesting output is on line 50. It is not going to be (2,3,4), otherwise the question would be too simple. On line 49 we cast an object o, which is a boxed value type myCoordinate, back to a struct, which unboxes it and saves to a temporary location on the stack. It is this temporary location that is then modified with new coordinates (2,3,4). The boxed value type in the form of object o is never updated, it cannot be changed. And the code on line 50 displays (1,2,3).
We can change the behavior of boxed value types through interfaces. Consider now the following modified Coordinate struct:
using System;
using System.Collections.Generic;
namespace BoxedValueTypesWithInterfaces
{
internal interface IUpdateCoordinate
{
void UpdateCoordinate(int _x, int _y, int _z);
}
internal struct Coordinate: IUpdateCoordinate
{
public Coordinate(int _x, int _y, int _z)
{
x = _x;
y = _y;
z = _z;
}
public void UpdateCoordinate(int _x, int _y, int _z)
{
x = _x;
y = _y;
z = _z;
}
public override string ToString()
{
return String.Format("({0},{1},{2})", x.ToString(), y.ToString(), z.ToString());
}
private int x;
private int y;
private int z;
}
class EntryPoint
{
static void Main(string[] args)
{
Coordinate myCoordinate = new Coordinate(0, 0, 0);
//no boxing because we overode ToString()
Console.WriteLine("Current position is " + myCoordinate.ToString());
myCoordinate.UpdateCoordinate(1, 2, 3);
Console.WriteLine("New position is " + myCoordinate.ToString());
//myCoordinate is boxed here
Object o = myCoordinate;
Console.WriteLine("Current position is " + o.ToString());
//unboxing here and creating a temp location
((Coordinate)o).UpdateCoordinate(2, 3, 4);
Console.WriteLine("Updating through cast: new position is " + o.ToString());
//no boxing here
((IUpdateCoordinate)o).UpdateCoordinate(2, 3, 4);
Console.WriteLine("Updating through interface: new position is " + o.ToString());
Console.ReadLine();
}
}
}
Again, what is the output on line 60? It is as expected, (2,3,4). Why? Here is why. On line 59, o, being an object that points to a boxed value type, is cast to IUpdateCoordinate. No boxing takes place, since o is already an object. Because Coordinate struct implements this interface, this cast emits a castclass operation which successfully casts object o to IUpdateCoordinate interface. When an entity (such as a class or a struct) implements an interface, it implicitly allows an instance of that interface to represent some part of itself. If you are now thoroughly confused, I suggest you read this post which should clarify what I mean. The UpdateCoordinate method is called virtually through IUpdateCoordinate interface and this updates the boxed value type referenced by object o. So, no temporary variable was created because no boxing/unboxing took place. Calling the method through an interface allows us to modify the actual boxed value.
I began this post by writing that structs should not be completely avoided as they can be handy when all you need is a simple structured object with value type semantics. If you find yourself making structs implement interfaces, perhaps this can be a good point to stop and reconsider your data type design…

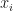 where
where  our task is to estimate
our task is to estimate  for
for  . Of course we may require to go outside of the range of our set of points, which would require extrapolation (or projection outside the known function values).
. Of course we may require to go outside of the range of our set of points, which would require extrapolation (or projection outside the known function values).
 and that
and that 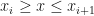 . We can re-write this expression as follows:
. We can re-write this expression as follows:
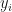 for
for 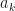 and
and  for
for  . Our linear interpolation is now taking a form of linear regression around
. Our linear interpolation is now taking a form of linear regression around ![[x_i, x_{i+1}]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+x_%7Bi%2B1%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002) . The cubic spline can be defined as:
. The cubic spline can be defined as: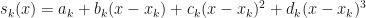
 and
and  coefficients, since
coefficients, since 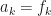 . Take
. Take  . The continuity condition (see P.R.Turner pg. 104) gives the following equalities:
. The continuity condition (see P.R.Turner pg. 104) gives the following equalities:
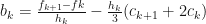
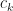 , we would be able to determine all the coefficients. After some re-arranging, it is possible to obtain:
, we would be able to determine all the coefficients. After some re-arranging, it is possible to obtain: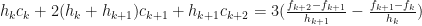
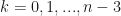 . This is a tridiagonal system of linear equations, which can be solved in a number of ways.
. This is a tridiagonal system of linear equations, which can be solved in a number of ways. . Using the above code we obtain the following results:
. Using the above code we obtain the following results:

