
I have recently attended a PyData meetup in London where Nicolas Radcliffe gave a nice talk on the concept of Test-Driven Data Analysis (TDDA). Here is a link to the slides that he presented.
Essentially, the idea behind TDDA is born from a well-known idea of Test Driven Software Development (TDSD or simply TDD). In TDSD, the test cases are written before the core code. This is often done to avoid developing solutions for specific scenarios and missing the edge cases. Take for example division. Everyone (hopefully) provides for division by zero, but what about integer division when a floating number is expected? How many times have you been caught out by this in a dynamic programming language like Python, staring at the code and wondering why every number comes out as zero? Developers who use TDSD specify at the start what the code should behave like and the constraints placed on the results.
Right now the practice of data science and data analysis very much lacks the structure of TDSD. I liked Nicolas’s 5th slide where he schematically shows the pillars of the data scientist’s workflow: trying, eyeballing and trying again until it makes sense. However, each stage of data analysis is prone to error. Starting from choosing the modelling approach down to interpretation of the results. Errors can be made in data pre-processing, model implementation, output gathering and even when plotting graphs. One of the main points of the talk was reproducible research. If every analysis is wrapped in a verification procedure that ensures that the same outputs are produced for the same inputs, then analysis bugs can be greatly reduced.
Another strong point of the talk was about using constraints. Much of the test-driven software development relies on constraints placed on the allowed inputs&outputs. In the data analysis, such constraints can be placed on data types, data value ranges, legality of duplicates, or even statistical and distributional properties. For example, can a value of an insurance claim be negative? What about a negative correlation between the insurance costs and the values of the claim?
I am hugely in favor of everything that makes software development more disciplined and the final result more robust. Thus you can see why I liked Nicolas’s ideas so much. It made me think about how and where I can incorporate TDDA in my work. Let’s take the work horse of data science – the least squares (standard multiple) regression. Can TDDA safeguard from common mistakes of applying regression and interpreting its results? I think it can. The quality of regression analysis and the ability of reproducing and reusing the regression model results will depend on the following parameters, all of which can be the constraints of TDDA:
- Inputs: number of input cases vs. the number of independent variables: too many or too few input cases can invalidate regression analysis. When the number of input variables is small compared to the number of independent variables (i.e. the attributes of regression), the regression converges on perfect but meaningless solution. Another possibility is that the variance-covariance matrix can be non-invertable. Alternatively, when one tries to fit regression to too much data, almost any amount of correlation between the dependent and the independent variable can become statistically significant. A large number of false positives is an unfortunate side-effect of big data used in the wrong way. A possible constraint can be a simple check if the number of cases is ≥ 50 + 8 * ‘# of independent variables’.
- Inputs: presence of singularity and multicollinearity: two regression attributes are singular if one of them is redundant (e.g. age and year of birth). Multicolliniear attributes are highly correlated, and in the case of standard multiple regression (as opposed to the step-wise regression, for example), can significantly impact/reduce the regression coefficients.
- Inputs: presence of outliers: everyone knows what outliers can do to the statistics like the mean and standard deviation. Likewise, outliers can significantly impact the coefficients of regressions. A constraint on outliers absence can be placed on the data.
- Output: normality and linearity of residuals: if regression was performed on non-transformed data, the residuals should always be examined. Skewed residuals may point to absence of normality in the input data, and non-normal input data may invalidate your prediction intervals if regression model is used to make predictions. Non-linear residuals may indicate that the originally suggested linear relationship between the dependent and the independent variables is inaccurate. Absence of normality is often dealt with data transformations (e.g. taking square roots or logarithms). Non-linearity will require re-visiting the original model (e.g. squaring or cubing the attributes).
- Output: homoscedasticity of residuals: the absence of homoscedasticity between the error and the predicted variable may occur if the response is related to some transformation of the dependent variable instead of its original form. In other words, the relationship of the two variables varies over time. For example, the relationship between age and income is very likely to have this non-linear shape, since income of young people varies less than income of people who are over forty. I should note that the presence of heteroscedasticity does not invalidate regression results, but it may weaken the strength of its interpretation. Again, data transformation can come to the rescue (e.g. taking the logarithm).
Here you go – we have come up with five constraints that can be placed on regression input and output to ensure robust data analysis. Luckily most analytical platforms like SAS or SPSS have built-in checks that flag when these constraints are not satisfied. But in case if you are playing with a regression tool from another package – watch out. There is no need to increase that figure of 90% (see slide # 10)…
![Sample from f(x)=2.0*exp(-2*x) over [0.01, 3.0]](https://codefying.com/wp-content/uploads/2016/10/rejfig_1.png?w=300&h=224)




 and
and  require to be scaled for longer observations since the product of probabilities quickly tends to zero, resulting in underflow. The code has a flag for scaling, and defaults to positive.
require to be scaled for longer observations since the product of probabilities quickly tends to zero, resulting in underflow. The code has a flag for scaling, and defaults to positive. and
and  makes a big difference to the final solution. I am providing two possible assignments. One, as described in part 1, setting approximately to the same values, adding to 1. And two, using Dirichlet distribution to create non-uniform assignment that adds-up to 1. I’ve noticed that the former results in more meaningful model parameters.
makes a big difference to the final solution. I am providing two possible assignments. One, as described in part 1, setting approximately to the same values, adding to 1. And two, using Dirichlet distribution to create non-uniform assignment that adds-up to 1. I’ve noticed that the former results in more meaningful model parameters. to the maximum observation in
to the maximum observation in  . This is needed because not all observation sequences will contain all values (i.e. 0, 1, 2). And the transition and emission matrices are accessed as if all the values exist.
. This is needed because not all observation sequences will contain all values (i.e. 0, 1, 2). And the transition and emission matrices are accessed as if all the values exist. :
: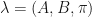 are very sensitive to the convergence tolerance, initial assignment and, obviously the training time-window. Calculating accuracy ratio as the number of correctly predicted directions is pretty much around 50%-56% (tests on more recent data produce the higher accuracy in this range). Thus, we might as well be throwing a coin to make buy or sell predictions. It is possible that EOD price moves are not granular enough to provide a coherent market dynamic model.
are very sensitive to the convergence tolerance, initial assignment and, obviously the training time-window. Calculating accuracy ratio as the number of correctly predicted directions is pretty much around 50%-56% (tests on more recent data produce the higher accuracy in this range). Thus, we might as well be throwing a coin to make buy or sell predictions. It is possible that EOD price moves are not granular enough to provide a coherent market dynamic model.